

Job Writer: Create From Reader
This option allows you to create Job Writers from an existing Job Reader, but keep both jobs independent from each other. Selecting this option allows you to more quickly create a Job Writer by pre-configuring certain options. However, this option is best used when at least one Data Sync file has been created from the reader.
To create a new Job Writer, right-click on the Job Reader that you would like to use as the base job, and select the New -> Create Job Writer from Reader option.
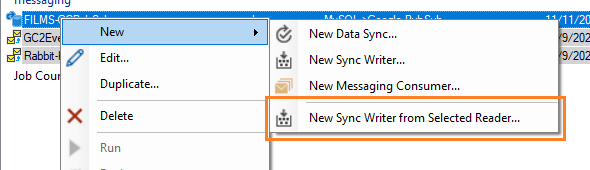
You can create as many Job Writers as desired. This option allows you to multicast data
replication to multiple, independent systems.
The Job Reader may also be an existing Direct Job (with an existing Job Writer), as long as
Sync Files are available for replay.
You can also daisy-chain the execution of Job Writers by using Triggers on the Job Reader.
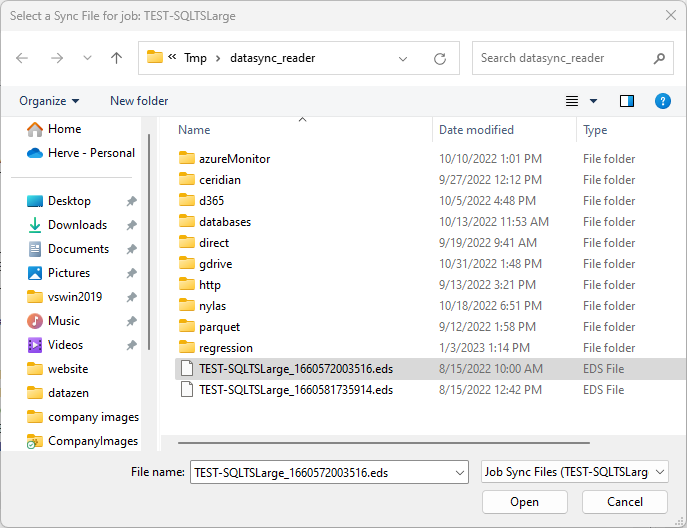
Select the Data Sync file you would like to use as the starting point for the Job Writer
and click OK.
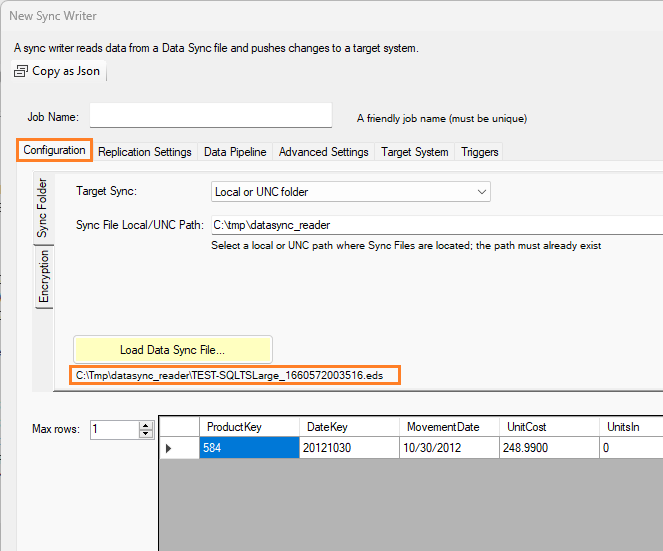
The data container in the Data Sync File will be displayed in the output.
The name of the currently selected file will be displayed; however, you can select another
Data Sync File by clicking on the Load Data Sync File... button. Doing so may show
a warning screen that some parameters (located on the Replication Settings tab) will be changed.
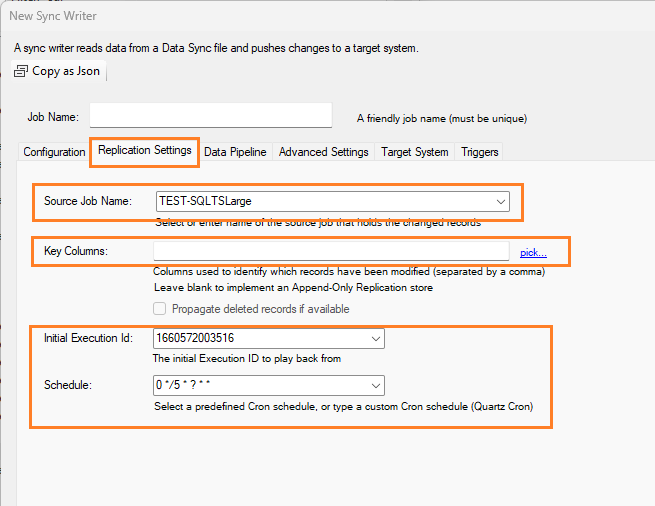
When selecting a Data Sync File, the following options are automatically set:
- Source Job Name: this field indicates the name of the Data Sync File to search for
- Key Columns: if the Data Sync File schema contains unique identifiers, they will be provided here; however, this setting can be blanked if you would like to push all records to the target system instead of only the changes detected
- Initial Execution Id: the initial timestamp value of the Data Sync File that represents the first Data Sync File used for this job
- Schedule: the Job Reader initial schedule; this can be changed as needed