

Introduction
DataZen is a data ingestion and replication platform that allows you to copy data from any source system into any target system, with optional automatic Change Data Capture (CDC), identifying and forwarding only the records that have actually changed. Because DataZen creates universal and portable Change Logs, data from source systems can be forwarded to virtually any target platform in the shape they are expected in.
DataZen supports three primary use cases, as further explained below:
- Data Lake Creation or Augmentation
- Enterprise Messaging Integration
- Application and Data Integration
DataZen's data replication strategy involve performing an initial load of data and continuously send changes to one or more target systems. Because these changes are stored in intermediate change logs in a universal format, they can be sent to any target system. DataZen forwards pushes data to target systems, enabling a highly scalable and Shared-Nothing replication topology.
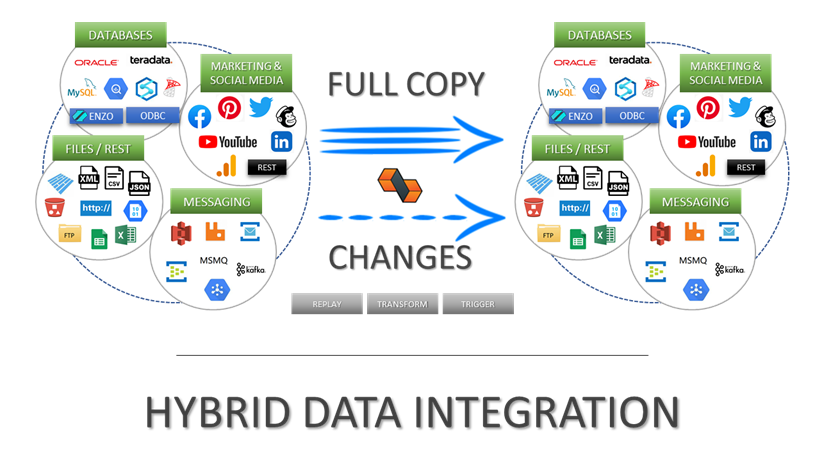
Any Source & Target
Initial Load & Change Capture
Shared-Nothing Push Replication
Inline Data Pipeline For Enrichment, Masking & Translation
Optional Synthetic Change Data Capture
Highly Resilient with Automatic Push Retries
Use Cases
DataZen supports the following high-level use cases:
Data Lake Creation or Augmentation
Build or augment and existing Data Lake from any source system, including
social media feeds, SaaS platforms, SharePoint Online, databases and more. This allows you
to build different types of stores, such as a Data Vault or a
specialized Data Lake for your reporting or operational needs.
HTTP/S Sources
When the source is an HTTP/S endpoint, leverage DataZen's built-in support
for OpenAPI, Swagger, Yaml, and Postman collections for faster setup. DataZen can keep the
necessary high watermarks and can be configured to handle paging as needed.
Parquet Files / CSV Support
DataZen supports Azure ADLS 2.0 and AWS S3 to simplify the creation
of Delta Lakes using compressed Parquet files, simplifying your cloud integration
architecture. You can also create comma-delimited files, JSON, or XML documents.
Quick Integration with Azure Synapse and PowerBI
Send your data to any target platform, including NO-SQL databases,
relational databases platforms, or Parquet files to enable centralized reporting
with PowerBI, Synapse Analytics, or other cloud analytical platforms.
See our blog on SQL Server Replication to Azure Parquet Files in ADLS 2.0 for
further information.
Enterprise Messaging Integration
As a Messaging Producer
Forward any change from a source system to any supported messaging platform (including Kafka, MSMQ,
RabbitMQ, Azure Event Hub...). If the source system does not offer a change capture feed, you can
use DataZen's built-in Synthetic Data Capture engine to detect and forward changes to data only.
As a Messaging Consumer
Listen for messages from any supported messaging platform (Kafka, MSMQ, RabbitMQ...) and forward them to
any other target system including databases, files, or HTTP/S endpoints.
As a Messaging Exchange Platform
Use DataZen's fully automatic messaging exchange engine to forward messages from one platform
to another. For example, you can configure DataZen to forward MSMQ messages into an Azure Event Hub.
Application and Data Integration
Quickly extract changes from any source system and forward to any platform by leveraging the native CDC (Change Data Capture) feed of the source system, or use DataZen's built-in Synthetic CDC engine, so that only the desired changes are send to the target systems.
Synthetic CDC
When a source system doesn't provide the ability to push changes, you can use DataZen's Synthetic CDC Engine to filter out records that have not changed, and only keep the records that were modified, and optionally records that were deleted.
Inline Data Pipeline
Leverage DataZen's inline data pipeline to enhance your data, apply data masking rules, add or remove columns dynamically and more.
Multiple Integration Patterns
Replicate your data across platforms based on your objectives, with support for four integration patterns:
Full Read,Window Read,CDC Read, and Window + CDC Read
Replay Changes
Keep DataZen's change logs and optionally replay previous changes on any target. Because change logs are portable, they can be archived and replayed in other DataZen environments.
Pipeline Architecture
To better understand how DataZen works, let's review the major components of the
DataZen Pipeline architecture.
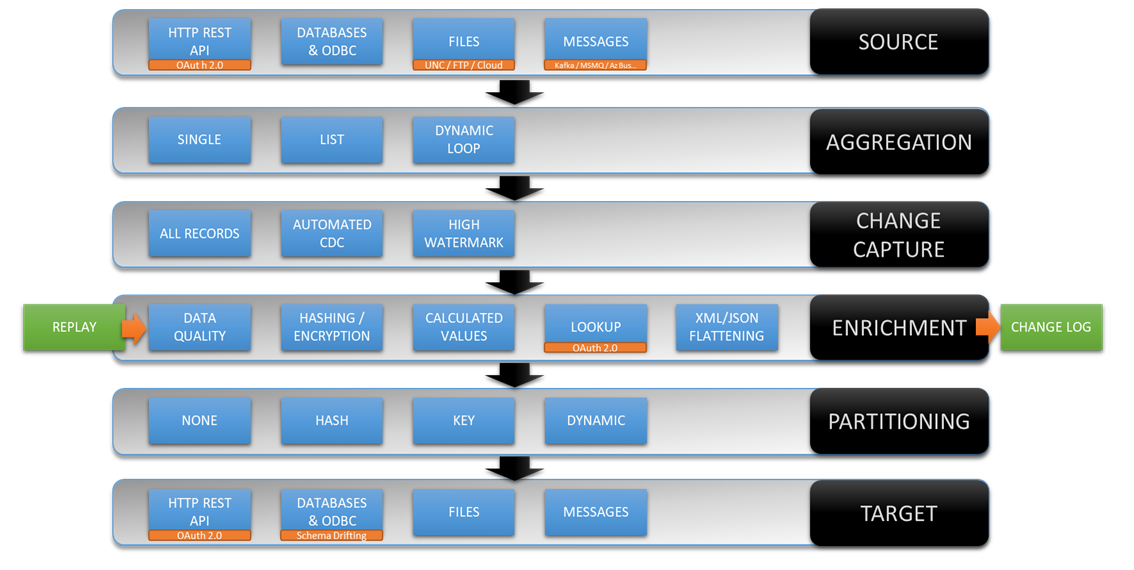
- Source: data is read from the source system (HTTP/S API, Database, ODBC, Enzo Server, Files...); uses an optional High Watermark to only read the necessary records
- Aggregation: data is optionally aggregated for certain data sources (ex: HTTP/S APIs) using Dynamic Parameters or from Files data sources
- Change Data Capture: when Key Columns are identified, the DayaZen Synthetic CDC engine eliminates records that have not changed or been deleted
- Data Pipeline: when defined, a data pipeline executes to enrich, filter, translate or transform data
- Change Log: the Sync File (Change Log) is created for most jobs at this point
- Partitioning: the Sync File is read and the data is optionally partitionned (depending on the target system)
- Target: the Sync File (Change Log) data forwarded to the target system