 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

Replicating SQL Server to Parquet files is quickly becoming a valuable function for
modern data management.
Here, we will discuss some of the key benefits of implementing a replication solution for SQL Server
to Parquet files
in Azure ADLS using Enzo's DataZen ingestion pipeline. DataZen can quickly be configured to replicate a SQL Server table, and
continuously forward changes on the table as individual Parquet files directly in
an Azure Storage Account ADLS 2.0. This allows organizations to build a Data Lake very quickly using the
preferred storage format for Azure Synapse: Parquet files.
The demo video in this article demonstrates how to configure DataZen to achieve this objective and shows you
how to query the data using Azure Synapse after the Parquet files are created by DataZen in ADLS.
It's all about increased speed and reduced costs.
Modern analytical platforms, such as Azure Synapse, use Parquet files as their underlying
Data Lake storage mechanism for performance reasons, including:
These are the primary reasons Parquet files are so popular with many analytics platforms, including
Azure Synapse. In addition to enabling efficient data reads within a single file, Parquet files
are also used by Synapse as the underlying mechanism to provide a Delta Lake.
A Delta Lake is used to store "delta" files that hold changes to
the original data. This way, updates to the primary/initial Parquet file is not necessary. Changes
are synthesized quickly so that when a query is executed against a Data Lake, the latest information
is presented to the user. This Delta Lake architecture works by leveraging Parquet files as well.
Not only can DataZen create Parquet files to be stored in ADLS for use by Azure Synapse, it
can also generate these "delta" files and load them directly into a Delta Lake used by Azure Synapse to
ensure the latest data is always available in the lake.
To replicate SQL Server in Azure ADLS storage, we configure DataZen to read data from a source table in a
SQL Server database, and choose a change-detection strategy (such as a high-watermark field) on the source
table so that DataZen can forward both
the initial set of records, and ongoing changes detected, as individual Parquet files.
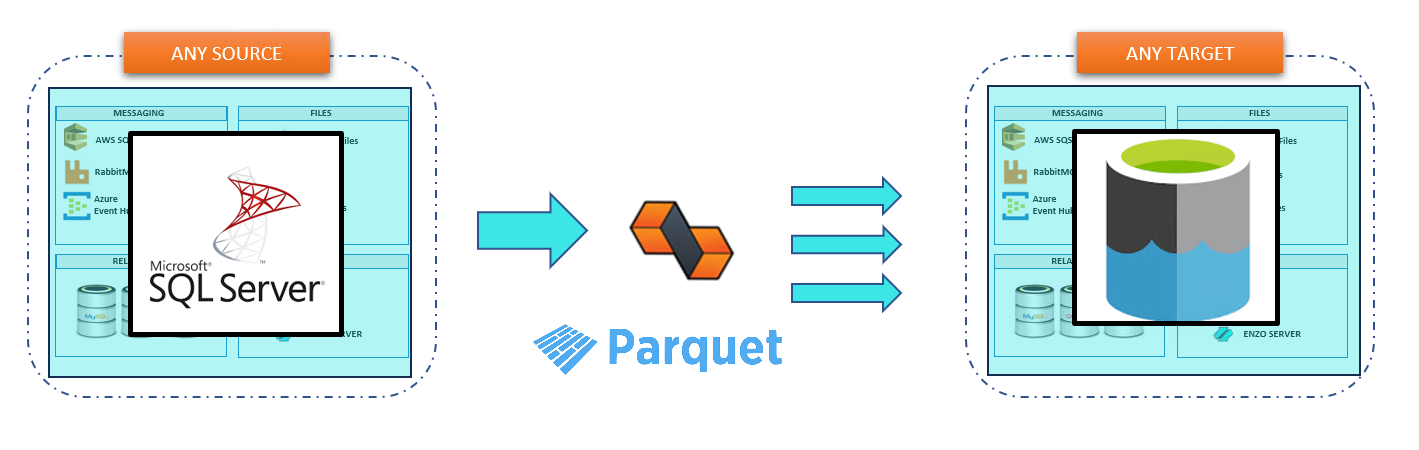
While this blog uses SQL Server as the data source, using Oracle, Teradata, MySQL, or an ODBC driver as the source system is just as simple.
In the demo provided in the Video, the High Watermark strategy is selected for speed and simplicity; however, DataZen
can use multiple change-detection strategies depending on the use case:
Generally speaking, it is best to use a High Watermark field for performance reasons and overall simplicity. In addition, using Synthetic CDC is not recommended when the target system is a file, because updating files usually introduces significant performance degradation.
Using DataZen to implement a replication topology from a SQL Server database to Parquet files in an Azure ADLS environment offers multiple benefits, including:
First and foremost, DataZen is a point-and-click configuration system. No custom development is needed and
just as importantly no complex ETL diagramming is involved. In other words, DataZen allows system engineers
to build their data replication topology without designing ETL jobs or compiling code, saving a significant
amount of time.
With DataZen, data engineers can build a data replication topology in ADLS using Parquet files in just a
few minutes.
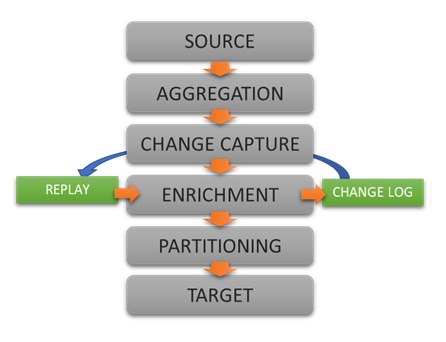
DataZen creates intermediate Change Logs that store modified or new records since the last capture. These Change Logs contain data in source and target agnostic format. The decoupling of source and target means that these Change Logs:
DataZen implements a push replication model, not a pull model. This offers multiple advantages including
the decentralization of the replication topology and a more secure environment. A push model eliminates
the need to build a master-slave architecture that controls the replication topology.
DataZen leverages a distributed, Shared-Nothing architecture that enables a
loosely-coupled replication model, which is far simpler to administer.
From a security standpoint, a push model eliminates the need to open inbound ports into your
internal network. In this scenario for example, DataZen pushes its changes logs using an HTTP/S connection
to Azure directly.
A key feature of the DataZen Parquet target is the ability to partition records across multiple files based on
source data and other parameters. To achieve this, data engineers use tokens in the naming
convention of the container, the ADLS path, and the file name.
This feature can be used to distribute data across folders by date token, such as year, month and day.
In addition, the source data can be used in the naming convention, such as a Country code, a LocationId value,
or any other data element.
DataZen sends change logs to the target systems in order, as soon as possible. If change logs cannot be sent due to network connectivity issues, DataZen will continue to capture changes from the source system and create additional change logs as usual. As soon as the network link is restored, DataZen will replay all the change logs that were not successfully sent, in sequence. This enables DataZen to work in environments that have sporadic network connectivity. The Push replication model enables DataZen to create its change logs continuously and transmit them when network connectivity to the cloud is restored.
DataZen also provides a data pipeline engine that allows data engineers to modify the data before it is saved in its change log and/or before it is sent to the target system. This is typically used to format specific fields, add one or more descriptive columns, translate date/time fields, and when needed mask or remove sensitive data. Unlike a traditional ETL (Extract, Transform, Load) job, the data pipeline engine is a lightweight ELT (Extract, Load, Transform) tool that functions as an inline set of small rules that are applied to each record.
Replicating SQL Server to Parquet files in ADLS is the beginning of how DataZen can improve the data sourcing needs in your environment. With a no-code data ingestion pipeline like DataZen, you can also address other critical data management functions, such as HTTP/S and hybrid data ingestion and messaging integration.
Integrate data from virtually any source system to any platform.
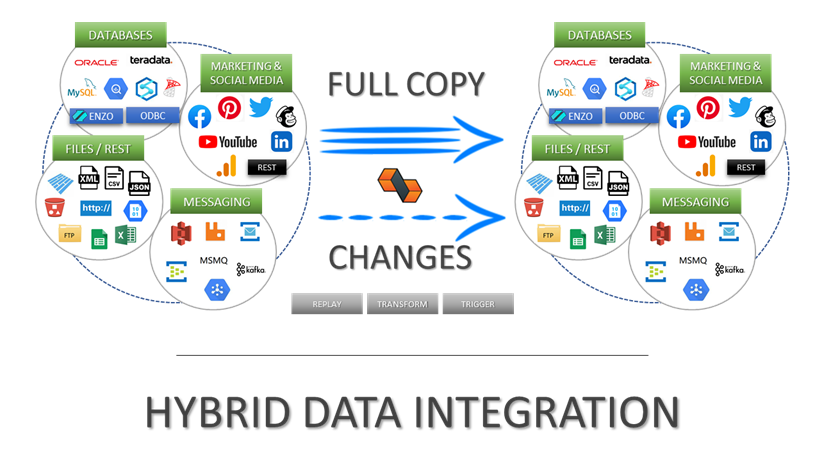
Support for High Watermarks and fully automated Change Data Capture on any source system.
Extract, enrich, and ingest data without writing a single line of code.
To learn more about configuration options, and to learn about the capabilities of DataZen,
download the User Guide now.
© 2025 - Enzo Unified