

Sync Agents
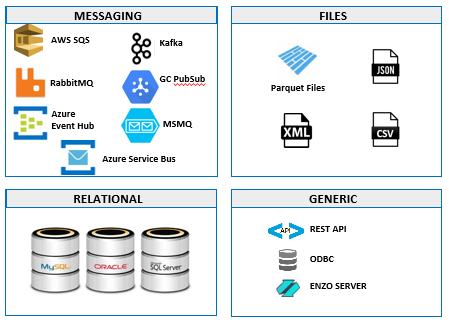
DataZen Sync Agents are designed to read and write from/to a wide range of systems, including messaging
platforms, files, relational databases, and generic drivers (such as ODBC drivers). In addition, Sync
Agents can read and write from/to thousands of HTTP/S REST data sources, some of which are pre-configured
for quick configuration.
Source & Targets
Read/Write from any source & target
Maintains high watermarks
Handles complex data shaping operations
Job Types
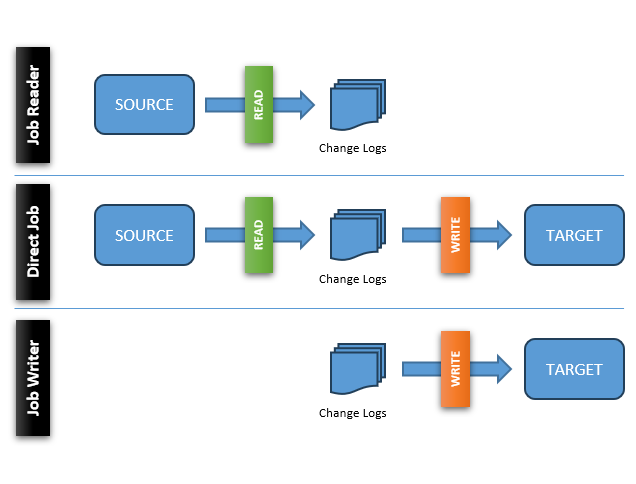
Job Reader: Saves Data in Change Logs
Direct Job: Immediately Push Changes
Job Writer: Reuse Existing Change Logs
Processing Pipeline
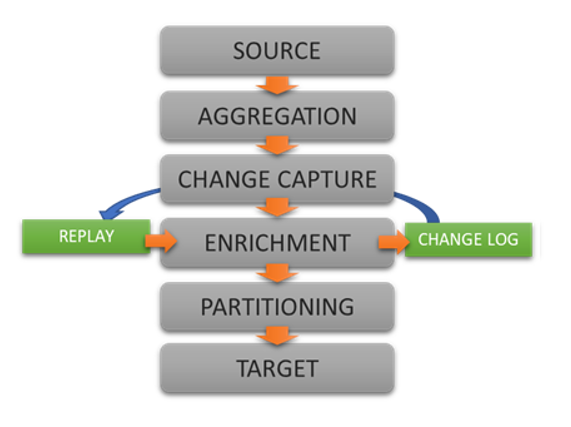
Read, Aggregate, Enrich
Partition & Push Changes
Replay Change Logs as Needed
A Data Sync Agent is needed to read from and/or write to a system. It is best to install a Data Sync
Agent close (for optimum network bandwidth reasons) to the systems that the agent will read from.
One or More Agents
For example, if you have a source system (ex: an Oracle database) in New York, and want to replicate changes to a Kafka endpoint in Atlanta, you could install two agents: one in each location. However, in most cases, you would use a single agent to perform both the read and write operation for most implementations; the agent would be installed close to the source system. If you have a large number of locations, you would likely install one agent per location. This can be useful for distributed sites that need to centralize data in the cloud.Resilience
By design, the Sync Agent is highly resilient. In the target system is not available for a period of time, it will continue to extract changes from the source system, and as soon as connectivity is restored to the target, it will replay the change logs that were missed, in sequence. As a result, Sync Agents can be installed in remote locations with sporadic or intermitent connectivity.Components
The Data Sync Agent is made of a few components:- Job Reader - a job that reads data from a source system
- Job Writer - a job that writes data to a single source system
- CDC Engine - internal engine that automatically detects changes (Synthetic CDC)
- Staging Store - stores configuration settings and state information of the source data
- HTTP/S Listener - a controller listener that DataZen Manager uses to manage the agent
- Sync File - a Universal Change Log that can be copied and played back
Data Sync Agents require a connection string to a Staging database stored in SQL
Server, as specified in the Installation instructions. Each agent is licensed separately.
Using LocalDB or SQL Server Express
You may use SQL Server Express or a LocalDB edition for the Staging Database.
Here is an example of a LocalDB connection string for the Staging Database:
Server=(LocalDB)\MSSQLLocalDB;Integrated Security=true
LocalDB should not be used for production workloads. SQL Server Express edition is supported, but in some cases the use of SQL Server Standard edition may be required depending on how large the staging tables need to be to keep state information.