

Job Reader: HTTP
Reading and extracting from HTTP/S data sources is made simple with DataZen. However, many options are available and may require fine-tuning depending on the service. This section provides a high-level overview for creating new HTTP/S Job Readers.
To create a new HTTP/S Job Reader, you must first have configured an HTTP/S Connection.
Then, from DataZen Manager, click on the New HTTP Job menu item:
If the service you are trying to call offers an Open API specification, Swagger definition, or
a Postman Collection, click on the Build from... icon. DataZen offers a few pre-configured
services as well. This special Wizard allows you to quickly configure HTTP/S calls and
save your own specifications locally for future use.

Build HTTP/S From Existing Specification
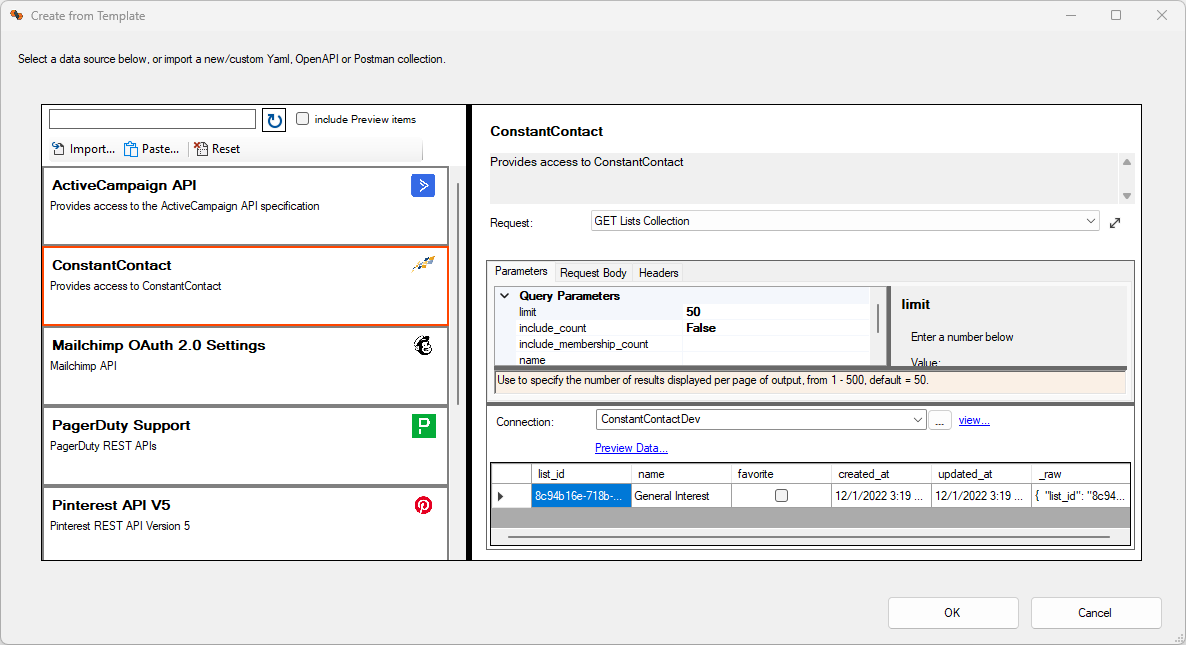
Building an HTTP/S call from an existing specification is made simple with the built-in HTTP/S builder. Choose from a list of existing HTTP/S templates or add your own Open API, Swagger, or Postman collection.
This screen has three sections: a list of existing services on the left, the list of
available HTTP/S calls top right, and a sample output bottom right. You can modify the
actual URL called and change default parameters before sending the request, including
HTTP Headers and the body for POST, PUT and PATCH requests.
Click on the preview data link at the bottom to send the request.
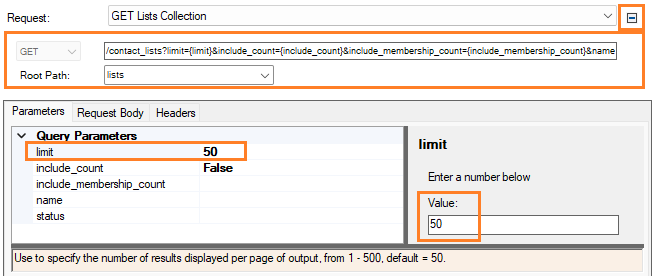
Set HTTP Options
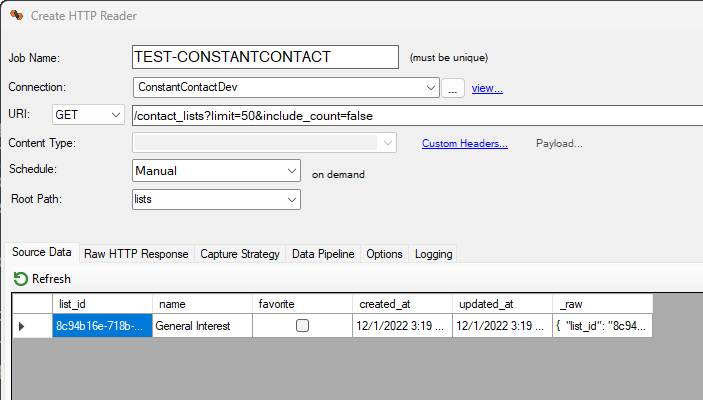
From this screen, enter a unique job name, an optional schedule, and modify the Content-Type and Payload for PUT, POST and PATCH operations. Of importance, the Root Path must be set correctly so that the payload returned by the HTTP service is transformed into rows and columns successfully. In this example, the ConstantContact HTTP service returns the actual data in a JSON document under the list array.
HINT: If you are not sure which path to set, blank out the Root Path field, and click on Refresh; the raw payload will be returned so you can further inspect it in the Raw HTTP Response tab.
The Root Path field should either be a valid JSON or XML path, depending on the
type of response provided by the service.
This field is case-sensitive.
Most HTTP responses provide a complex result set either as a JSON or XML document.
You can automatically convert an HTTP response object into rows and columns, with a
few limitations. DataZen's transformation logic inspects the response body from
the path provided (ex: $ for a JSON root document). All child nodes under the path
provided will be returned as a separate column with the most appropriate data type.
If a child node is itself an array, or a nested document, a string will be returned
with the full JSON content of the node.
For a JSON Document: provide a JSON path that returns a node, preferably an array.
For example, specifying data returns the content of the 'data' node with two columns:
'id' and 'bob', and a row per entry found in the 'data' array.
{ "data": [ "id": 123456, "name": "bob" ] }
For an XML Document: provide a valid XPath query that returns a value, preferably with
repeated children. For example, /root/data returns the content of the data node with
two columns: 'id' and 'bob'.
<root><data><id>123456</id><name>bob</name></data></root>
Set Replication Strategy Options
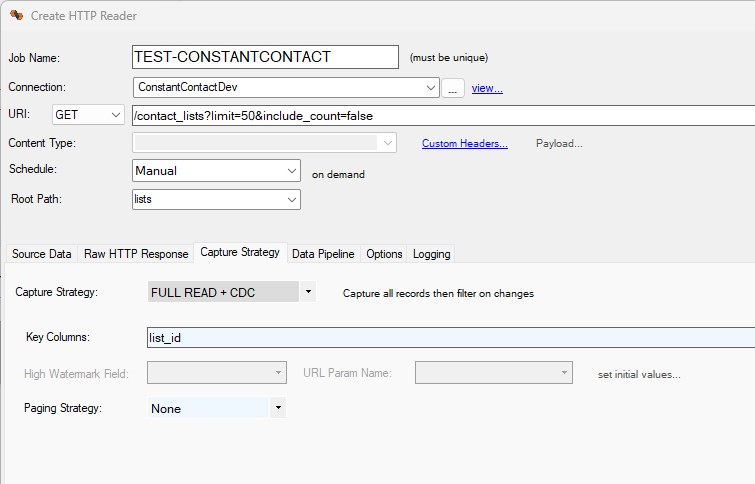
The capture strategy allows you to control how data is ingested and filtered by
DataZen's internal engine. A FULL READ strategy will always call the endpoint with
the same parameters as specified by the URI. This strategy is best when the
endpoint provides "streaming" data already (such as a CDC stream), or returns a
relatively constant list with changing field values (ex: flight status). The WINDOW READ
strategy is best when the underlying data provides a continuous stream of data (ex: Twitter)
or a forward-only log. The WINDOW READ strategy requires the specification of a
High Watermark (ex: last tweet id, or last timestamp).
The CDC option, available for both FULL READ and WINDOW READ provides client-side filtering
by DataZen using its built-in Synthethic CDC engine. The CDC option requires the use of
Key Columns (one or more) to identify records uniquely. When configured, DataZen will
automatically exclude records that have not changed since the last call. As such, the CDC
option provided by DataZen is stateful and requires an initialization of source records.
Capture Strategies
Four capture strategies are available:- FULL READ: read all records, all the time. No additional filter or change data capture is applied.
- FULL READ + CDC: read all records, all the time; however, incoming data is filtered by DataZen based on previous captures using Key Columns (Synthetic CDC)
- WINDOW READ: read all records from the last pointer (high watermark); this is usuall the maximum value of a timestamp or an integer taken from the data
- WINDOW READ + CDC: read all records from the last pointer (high watermark) then filtered by DataZen based on previous captures using Key Columns (Synthetic CDC)
Key Columns
Key Columns are used by the DataZen Synthethic CDC engine to determine which records were added, modified, or deleted (when applicable). One or more fields can be selected. This field is required when using a CDC strategy. Any data type is allowed for CDC tracking.
Key Columns are not required if the HTTP source system is itself a change-log (such as a Kafka endpoint) or if you can use a High Watermark to fetch changes.
High Watermark
A High Watermark (or pointer) is required when using a WINDOW strategy. This field
should be an integer/long, date/time, or timestamp value. Selecting other data types
could result in missed data or errors. You can specify initial values for the pointer
field if needed by choosing set initial values....
See the High Watermark help section for more information.
Paging Strategy
A paging strategy allows you to fetch source records in chunks. When doing so, DataZen
may call the HTTP endpoint multiple times with different parameters to fetch the "next"
set. Certain HTTP APIs limit the number of records returned by applying a
maximum (limit) to the data set (for example, Twitter). Setting this value correctly requires
an understanding of the paging capabilities of the HTTP API being queried.
The following paging strategies are available:
- None: No paging logic is applied; the HTTP API is called once
- Simple Offset: DataZen keeps a count of records retrieved; it uses the current record count as its "next" page using the URI Parameter specified Simple Paging: DataZen keeps a count of calls made; it uses the "page" count as its "next" page using the URI Parameter specified
- Reference Link: DataZen uses a full HTTP URI provided within the JSON HTTP response and uses it "as-is" for its next call. This setting requires a JSON or XML Path to be specifed (see the JSON or XML Path section below)
- Bookmark/Token: DataZen uses a Bookmark or Token value provided within the JSON HTTP response and uses it for its next call using the URI Parameter specified. This setting requires a JSON or XML Path to be specifed (see the JSON or XML Path section below)
Dynamic Parameters
Dynamic Parameters allow you to specify variables to be used as part of the HTTP call;
each row of values will be executed as a separate HTTP call. The values to be used can
be stored in a database table so you can control the parameters externally.
To use the parameter, use this notation within the HTTP URI: {{@param.variablename}}
For example, if you would like to fetch the twitter feed from multiple Twitter accounts,
you would create a Dynamic Parameter that returns the Twitter ID for these accounts; here
is a sample SQL command that returns 3 IDs, and the column name is 'userId':
SELECT '15358364' as userId
UNION SELECT '14934774'
UNION SELECT '2389949911'
Then, the URI would look like this (note the use of the userId parameter in the URI):
https://api.twitter.com/2/users/{{@param.userId}}/tweets?expansions=entities.mentions.username&tweet.fields=created_at,author_id&user.fields=username&max_results=100
When the job executes, it will replace the 'userId' parameter for each available entry.
If you use a High Watermark along with Dynamic Parameters, the first column returned by the Dynamic Parameter SQL command must be unique; internally DataZen uses the first column as the key for storing the last known High Watermark value.