

Job Writer: Drive
To save data into files, use a Drive connection. To use a specific file type, select the desired File Format. The following file types are supported:
- CSV
- JSON
- XML
- Parquet
Date Field Identifier
The Date Field Identifier changes the date used for date tokens. Date tokens can be used as part of the path and/or file name itself. By default, the date token (if left blank) is the job execution date/time. You can choose a source field that represents a date/time instead. Using a source column allows you to group records into time windows. The following date tokens are avaiable:
- yyyy
- yy
- mm (month)
- dd
- dow
- doy
- hh
- nn (minutes)
- ss
Path and File Name
You can provide a specific path or folder in the Path Override field to write the file into. The File Name should include the file extention; it is not automatically added. Both fields accept DataZen functions to control where files will be created.
For example, the following settings will create a target folder every year, based on the Date_of_Birth field, and a seperate CSV file per country field.
- Date Field Identifier: Date_of_Birth
- Path Override: c:\tmp\csv\[yyyy]\
- File Name: customer_{{country}}.txt
Shadow Copy
When updating existing files, DataZen can use a local copy of a file with an aging policy. This option improves performance by not requiring a download of a file to update first, if the file is not too old. However, this option assumes that the file was not modified by another process.
Example: Parquet Target
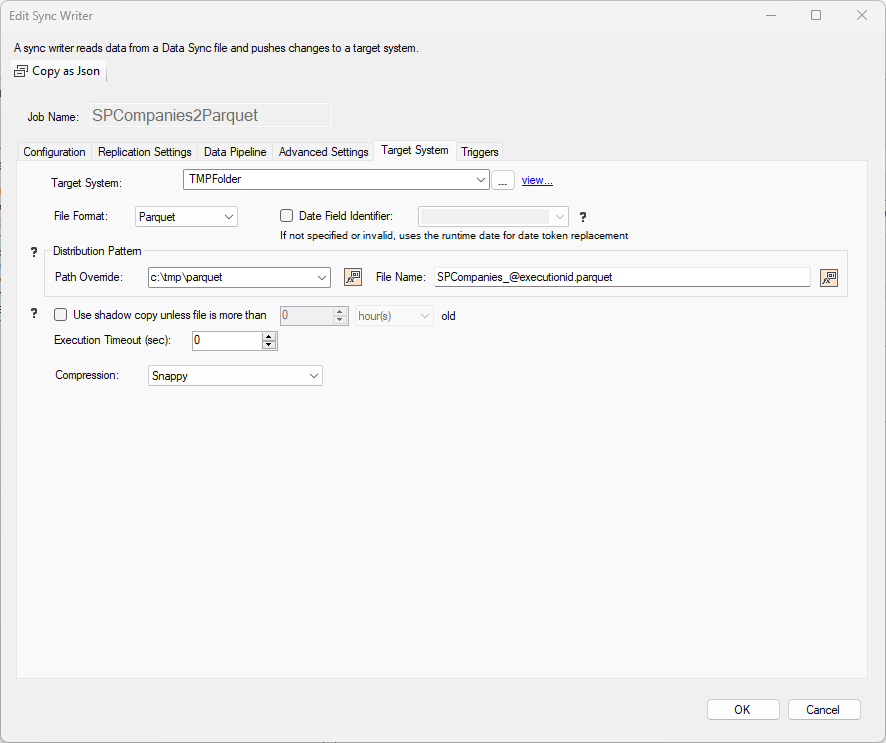
In this example, the settings use a Parquet file target on the local drive using the specified Path Override. The name of the file will be different for each execution since the name contains the @executionid variable.
The Parquet will will use the Snappy compression algorythm.
The Date Field Identifier used will be the execution date/time of the
job; however, since no date token is being used this setting will be ignored.
The Shadow Copy is not set; this is not normally needed when using
local files.