

Job Reader: Drive
DataZen allows you to read files (one or more) from Drive Connections, including cloud drives and FTP sites. The following file types are supported:
- CSV: read from delimited or fixed length files
- JSON: read JSON documents
- XML: read XML documents
- Parquet: read Parquet files
Depending on the file format, certain options vary.
Settings
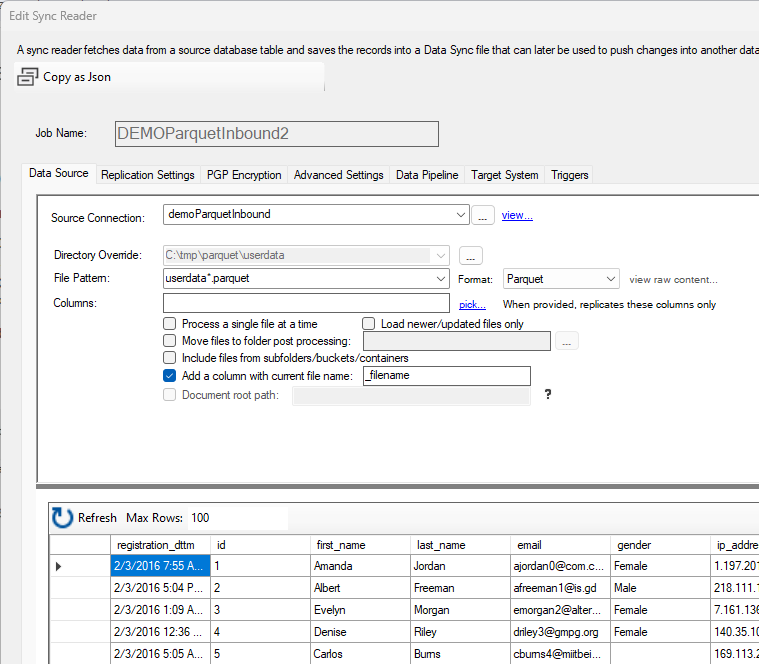
To read from a source file, choose your Drive Connection and optionally override the default directory. Then enter the file pattern to use. This field allows you to use * and ? wildcards to perform the data extraction on multiple files. In this example, any file matching this pattern will be read: userdata*.parquet. You can optionally specify a file used as the one containing the expected schema, and further limit which columns to read from by listing them in the Columns field.
Although DataZen can attempt to automatically detect the file type provided, certain options are only available when selecting the type from the Format field.
The following advanced options are available for all file types:
- Process single file: if left unchecked, all files are read and assumed to be part of the same data set; the same Job ID is used as well. This option has an effect on how unique records are treated. Use this option is all files to be processed should be considered different batches.
- Move files to folder: when selected, files are moved to a different folder after being successfully processed.
- Include files from sub folders: Use this option to walk down the sub-directory structure to find additional files.
- Add Column with file name: Use this option to add a trailing column with the name of the file the current record comes from
If the documents are XML or JSON, the Document Root Path option becomes available.
This option Use the path provided to filter the document content or read from a specific path.
The root path is case-sensitive.
When clicking the Refresh button, only the first file is read to show a preview of the data. In addition, while certain data types are automatically detected (such as integers), date/time fields are not (they are returned as string values). You can use the Data Pipeline to create additional fields and perform limited data transformations as needed.
If the documents CSV, additional options are provided allowing you to select the Column Delimiter or the list of fixed lengths field, if the files have a header row and if a comment delimited is expected.