

/capabilities/cdc
CHANGE DATA CAPTURE
The Change Data Capture feature of ENZO has been replaced with the introduction of ENZO DataZen, the Any to Any Data Replication Engine. DataZen offers significantly greater flexibility to identify changes from any source system, with multicasting and replay capabilities, and supports thousands of internet data sources natively.
Introducing DataZen
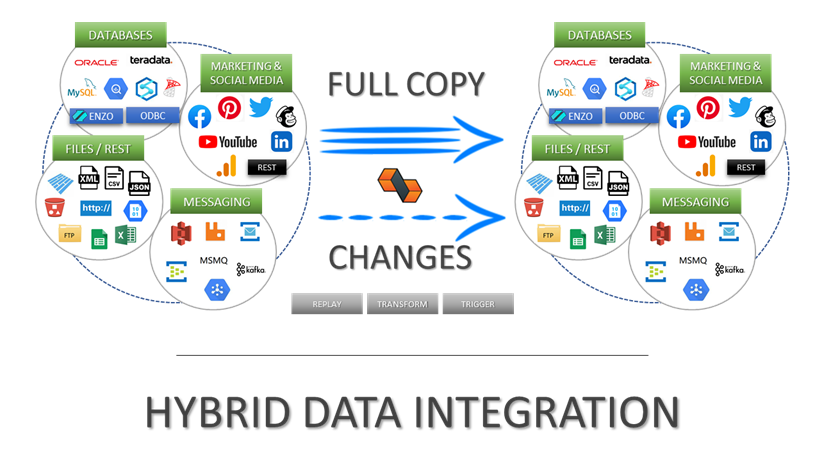
Automatic change data capture (CDC)
Access REST, CRM, ERP and Social Media
On-the-fly Parquet/JSON/XML file replication
Any-to-any messaging hub forwarding
Full replay and forward capabilities
Architecture
At a high level the CDC engine is designed to detect changes from source systems and stores them in an CDC Store. Separately, each listener holds a pointer to the last successfully sent change record from the CDC Store, and plays back all changes from that point on. This architecture ensures that source and destination systems are completely decoupled. In addition, since the CDC Store stores information as a JSON payload, it is possible to forward the change records to any destination system including generic webhooks.
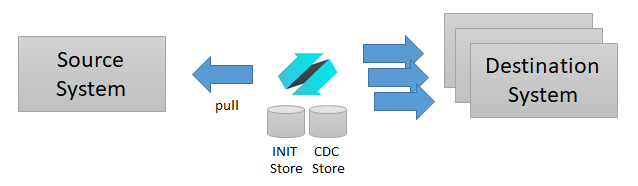
Enzo Server pulls data changes from a source system and stores detected changes in the CDC Store.
It is also possible to extract all current records in their initial state before starting the CDC process. When configured to do so, a complete extract of the source system is performed and stored in an INIT Store. This makes it possible to build a complete replication mechanism between two or more systems.
Pre-Requisites
Before you can setup a CDC pipeline and listener, you need to configure the appropriate adapters and the required Connection Strings. See the Configuration Settings section for information about configuring adapters. And see the Connection Strings section for details on how to create connection strings.
Two connection strings are needed to setup CDC: a loopback connection to Enzo Server, and a connection to an external SQL Server database that will be used for the CDC and the INIT Stores.
Make sure that the SQL Server connection string uses a Default Catalog.
Pipeline Adapter Config Setting
Before creating pipelines and listeners, you need to first create a configuration setting for the Pipeline Adapter. The configuration settings require two values: the connection strings you created previously. One of them points to Enzo Server directly (using the 'sa' account preferably) and the other points to a SQL Server database.
It is important for the storeConnectionString setting to point to a SQL Server database with the Default Catalog specified and poiting to an existing, but empty, database. The Pipeline Adapter will create the necessary tables automatically.
Create a Pipeline
To create a new pipeline, select the Pipeline Adapter, and click on the Pipelines tab. From here you can click on the NEW icon to create a new pipeline.
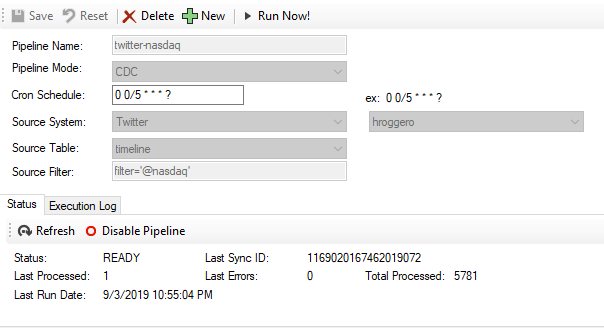
- Enter a unique pipeline name
- For the pipeline mode, select Sync, CDC or Sync & CDC (see below)
- Enter a valid cron schedule, which will be the polling interval on the source system
- Select the source system (the adapter must be loaded) and a configuration setting
- Select the source table or remote object
- Enter a filter if required (required for the Twitter adapter)
- Click Save to create and start the pipeline
Pipeline Mode
You can choose between three modes for the pipeline:- CDC: Creates a CDC pipeline only; pulls changes from the source system into one or more listeners.
- Sync: Creates an INIT operation only; used to copy data out of the source system into listeners; no CDC.
- Sync & CDC: Creates both an INIT operation and CDC pipeline to enable a complete replication.
Create a Listener
Once a pipeline has been created, you can create one or more listeners. Select the pipeline you want, then click on Add Listener.
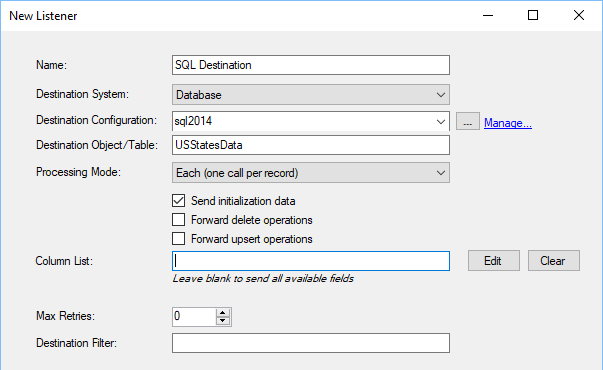
- Enter a unique listener name
- Select a destination adapter (or HTTP Webhook)
- Select a configuration setting for the adapter
- Select a table/resource destination name
- Select a Processing Mode (see below)
- Choose what will be sent (INIT, DELETE, UPSERT operations)
- Choose the list of columns to send (leave empty for all)
- Enter a maximum number of retries
- Enter an SQL-like filter to limit the data being sent over
- If requested, specify a list of parameters needed for the adapter
- Click OK to create the listener and start the replication
Processing Mode
You can choose between two processing modes for the listener:
- Each: Calls the listener once for every change detected in the source system.
- Once: Calls the listener only once at every interval, if a change was detected.
INIT Option
When selecting the INIT option, every record from the CDC INIT Store will be sent first; once this operation completes events from the CDC Store will be forwarded.
Optional Parameters
Some listeners require additional parameter mapping. For example if the destination system is a SharePoint list, a keyField needs to be specified. This can be a constant value, or the value contained in a field from the event. The parameter screen provides additional details for available options.
SQL Server Listener
You can specify a relational database for a listener; when doing so you will need to create the table before saving the
listener, or the listener will fail. To help you create the proper schema for the destination table, a
VIEW/EXECUTE DDL STATEMENT button will be visible when choosing Database as the destination. Clicking
the button will show you the statement used to create the table, and you will have the option to create the
table.
The DDL command will only work if the destination table is a SQL Server database.