PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰


In this blog I discuss some of the key constraints that hinder organizations from
building data warehouses quickly, and some of the techniques available to address them.
The scope of this blog is to discuss common constraints that apply to organizations of
all sizes. While larger organizations will face additional challenges, such as
storage performance or parallelism optimizations, a number of issues appear to
affect organizations of all sizes which have a tendency to significantly slow down
data warehouse projects. In addition, while the scope of this discussion is in the
context of building data warehouses, the constraints discussed also apply to data marts
and smaller operational databases using relational database stores; as a result, the
term data warehouse is intended to be loosely defined in this blog post.
This blog will address the following three main areas that notoriously impede the ability
to execute quickly on data warehouse projects:
Let’s evaluate how each challenge noted above can be resolved using simple techniques available through modern data platform tools.
A key challenge in building a data warehouse is the ability to
access the source data quickly and easily to perform initial data exploration, and to
import the data into a database. For example, customer records can be hosted on
SaaS platforms, such as SalesForce, Microsoft CRM, SharePoint Online or other CRM
systems; the ability to discover the data, how it’s stored, and how to filter it is
one of the first steps in any data warehouse project.
Most SaaS systems (including traditional on-premise systems) expose their data using
Application Programming Interfaces (API), which traditionally requires software
development skills to consume, or the use of an Extract Transform and Load (ETL)
tool (such as SQL Server Integration Services (SSIS), MuleSoft, Informatica or other tool).
Other ways to access this data is through regular data export options provided by the
SaaS vendor, which may be cumbersome, and not easily automated. The simplest ways to
extract hosted data may be by running a built-in report from the SaaS vendor. Last but
not least, you may be able to find an ODBC driver for the SaaS system that hosts the data
you want to extract.
However, none of these options allow you to ingest the hosted data into a data warehouse
quickly and easily. API programming requires advanced software development skills, and
ETL tools (including SSIS) requires domain-specific knowledge which can take years to
fully learn. ETL tools also usually require some level of coding, which makes the tool
harder to use. And while data exports are useful for accessing data in Microsoft Excel
or Google Sheets, they are not an appropriate option to ingest data into a data warehouse
because it is hard to automate. Last but not least, while ODBC drivers provide a relatively
simpler data access option for SaaS data, they usually require drivers for every
workstation that need data access and are limited in their capabilities beyond data
exploration (for example ODBC drivers have no data refresh, caching or scheduling
capabilities), which explains why they are normally used alongside ETL tools.
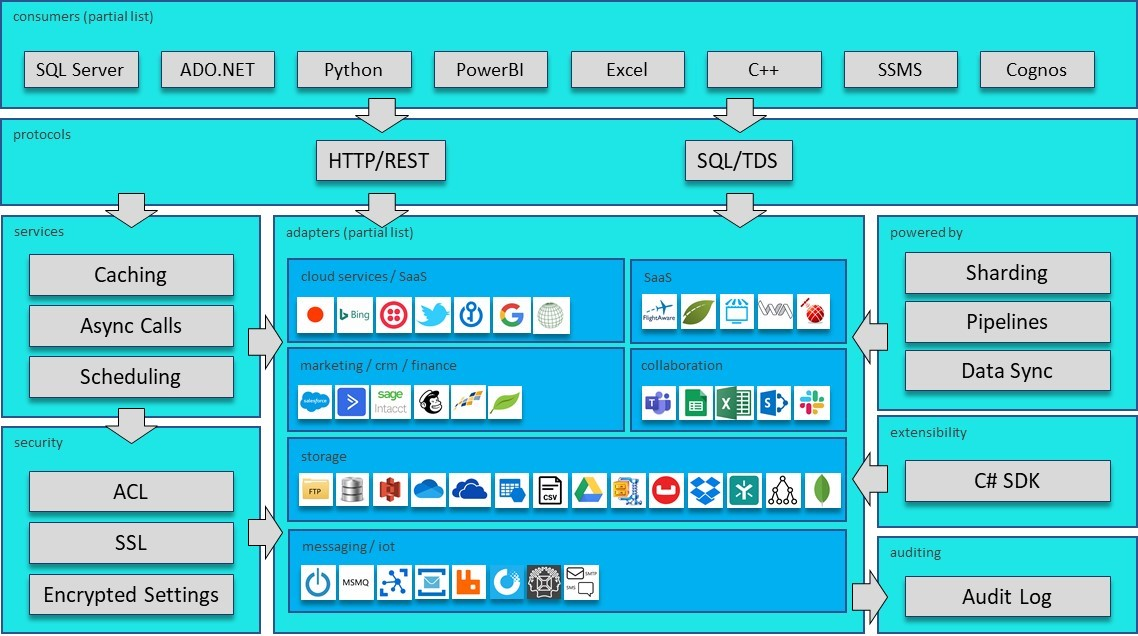
In order to solve the previous challenges, we created Enzo, an inline data service
technology that can abstract APIs transparently, so that they can be accessed using
direct database requests in real-time. Enzo makes SaaS APIs look like a native SQL Server
database. In other words, you can call APIs directly from SQL Server, for both read and
write operations. This allows power users to easily and quickly ingest SaaS data by
executing SQL commands against the SaaS system, without requiring drivers to be installed
on the client workstation (Enzo can be installed centrally as a server).
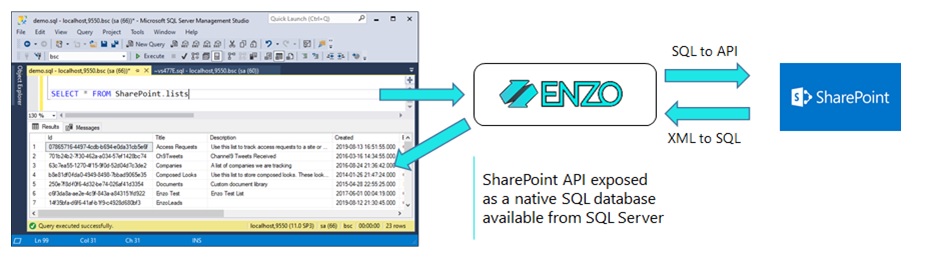
Because Enzo looks like a SQL Server database, ingesting data into SQL Server becomes a
simple task. For example, inserting data into a database table from an Excel file can
be performed using a single SQL command; the SELECT … INTO command below reads from an
Excel document, and imports the data directly into SQL Server. This is a good option
for ad-hoc data access and exploration; we will look at a more systematic and
automated option next.
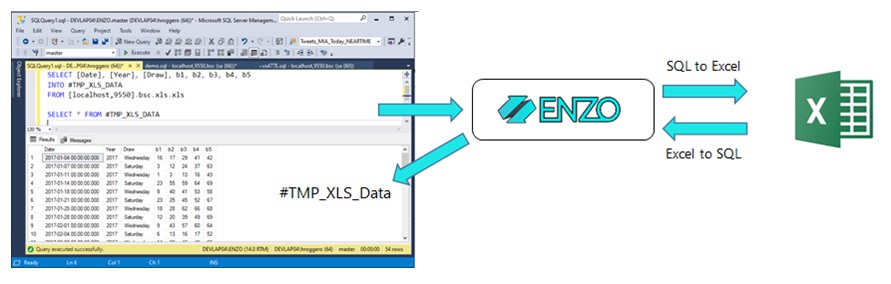
As discussed previously data exploration and ah-hoc requests for data ingestion is an
important aspect of building a data warehouse. The next challenge is the ability to
import the initial data and refresh the data on a given interval, or on demand,
since data is rarely static. Importing data also means that the data warehouse has the
right columns and data types. This data mapping exercise can be complex and error prone.
Traditionally the only option available to refresh data is to use an ETL tool (such as SSIS);
however, as discussed previously, this can be rather difficult and requires advanced
knowledge of the tool and possibly software development knowhow. Larger organizations
will have the knowledge and skill to leverage ETL platforms; however, they still require a
significant investment in time and effort.
Enzo offers two built-in data integration options: Data Sync and Data Pipelines.
Data Sync is used for data replication allowing you to build and refresh
data warehouse tables. Data Pipelines is a Change Data Capture (CDC) technology that can
be used for more advanced event-driven data integration scenarios, turning changes from
source systems into individual change data capture events that are forwarded to a message
bus and can be processed individually on multiple destination systems. We will discuss
Data Sync in this blog as it is more closely related to the topic of data refresh.
The Data Sync feature of Enzo allows you to create background jobs that will create the
target table automatically, perform the initial data load, and refresh your data warehouse
tables directly. After the data is read from the source system, records in the data warehouse
are either updated or added automatically, at the specified interval.

You can monitor Data Sync jobs using Enzo Manager and manage their execution directly.
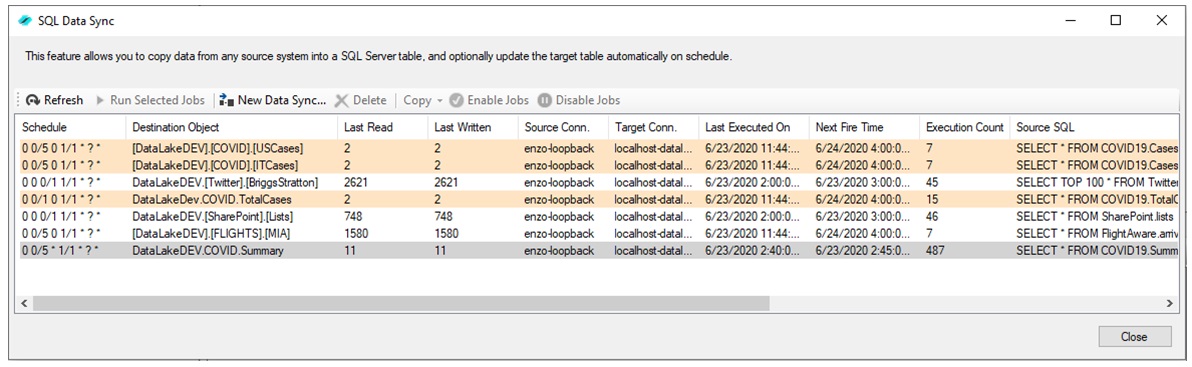
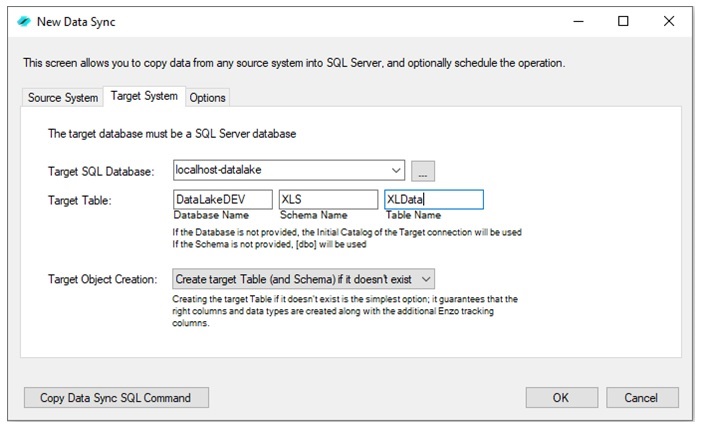
When creating a new Data Sync job, you can choose to create the destination table
automatically; additional options include scheduling the data refresh, and whether
the data will be continuously appended to the table (to build a history table) or be
upserted (to represent the latest data available) with optional delete cascade. Creating a new
Data Sync job using the
Enzo Manager tool is quick and easy, and requires no coding. With Enzo, you can create a
data warehouse within minutes with automatic data replication regardless of the source of the data.
Consuming near-time data is usually an append-only ingestion pattern, in such a way that
data is only added to a data warehouse table. A Twitter feed and IoT sensor metrics are
examples of data that is never updated. Other types of real-time data sources do require an
update, such as weather data. The challenge with near-time data ingestion is the frequency
of the refresh operation and the ability to continue from where the data was last read for
some source systems (such as Twitter).
Considering most near-time data sets are either available as XML or JSON documents, ETL
tools and/or ODBC drivers are still needed to ingest this kind of data, and a significant
amount of time is required to transform the data into a SQL table output. As a result,
while existing technologies can be configured to consume near-time data, it can still be
a challenge to build such an ingestion pattern.
As previously discussed, Enzo offers Data Sync and Data Pipelines for data replication,
both of which can be used for near-time data ingestion. The primary difference with near-time
replication is the frequency of the data refresh; the data replication pattern itself is the same because
Enzo abstracts the data sources as SQL tables and performs an UPSERT operation against the target table.
For example, a Data Sync job can be configured to capture tweets that mention COVID19 (using the
Twitter adapter) every 5 minutes, and store the information into a data warehouse. The SQL command below
limits the number of records requested to avoid overloading
the Twitter service with too many requests (your Twitter account may be throttled if you query Twitter too frequently):
SELECT TOP 1000 * FROM Twitter.timeline WHERE filter='covid19'
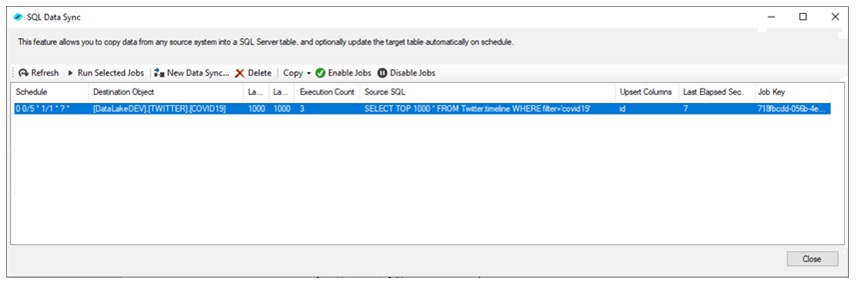
As we can see from the screenshot the data has been ingested into a SQL Server database, and is being refreshed every 5 minutes automatically. Depending on the source system API you may be able to refresh at a faster rate; in this example fetching 1000 records from Twitter and loading the data in SQL Server took about 7 seconds; as a result, you could safely perform this update every minute.
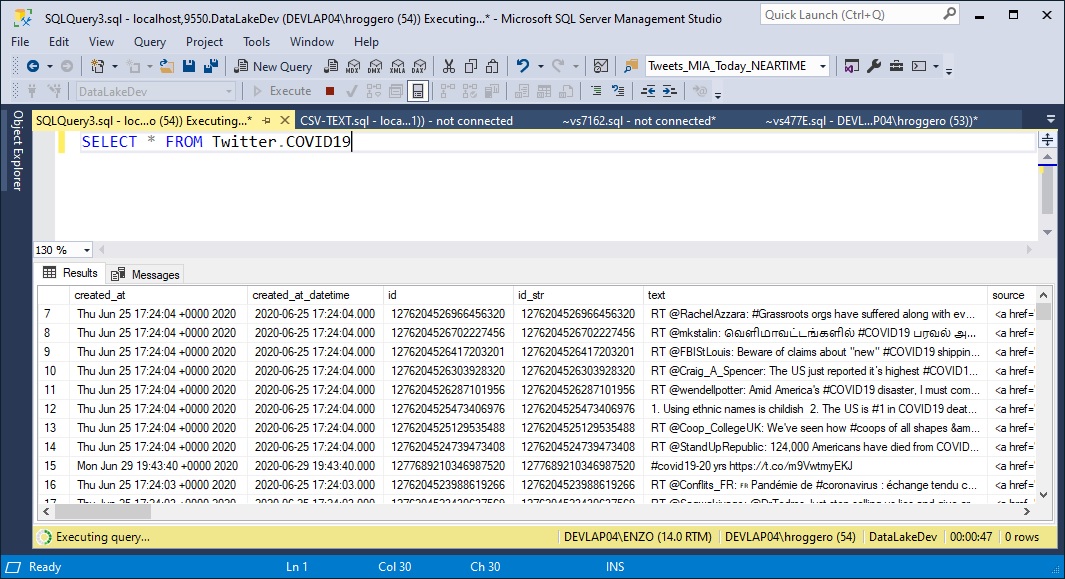
Querying the target table table shows the tweets captured by Data Sync. The table was automatically created, and new data is being added every 5 minutes.
While accessing remote data can be done using simple technologies, building a data warehouse
can introduce a number of challenges that requires the use of advanced technologies, such
as ETL tools. While ETL tools and ODBC drivers can be used together to solve some of
these challenges, they usually require a significant amount of development time and
domain-specific knowledge, and can be hard to maintain over time. Enzo’s Data Sync
technology can drastically simplify data exploration, data loading, and data refresh
without using ODBC drivers or ETL tools.
To try Data Sync at no charge,
download the latest edition of Enzo Server and see how you can build your data warehouse
in minutes!
© 2025 - Enzo Unified