PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

This blog discusses various options to import data feeds from multiple Social Media platforms
(such as YouTube, LinkedIn, Twitter, Facebook/Meta, Pinterest and more) into the Azure platform as Parquet files, so that you can query them
directly using simple SQL commands with the Azure Synapse service. This guide is intended to provide a high level overview of how
the overall solution works and outlines key considerations when access Social Media platforms.
This article is divided into three seperate sections:
DataZen supports a large number of connection types, including databases, FTP sites, cloud drives and REST endpoints.
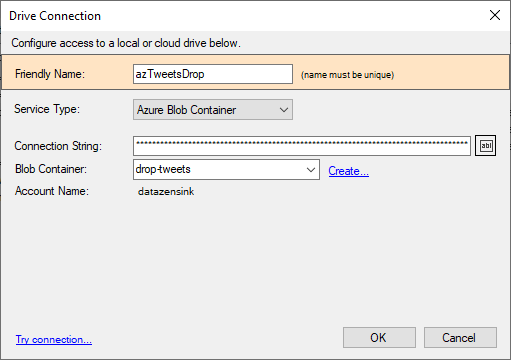
To connect to an Azure ADLS Storage endpoint, DataZen simply needs an Azure Storage connection string. You can obtain your Azure
Storage Connection String directly from your Azure Portal. If you would like to create a new container, you can click on the
create... link.
Next, you will need to configure DataZen to authenticate against one or more REST endpoints exposed by the
Social Media platforms you would like to extract data from. Each configuration setting can use different rate limiting
options, allowing you to control how often you call the endpoint.
Note that DataZen can help you generate OAuth 2.0 Authentication Tokens easily and, when provided by the remote service, use Refresh Tokens for automatic renewal.
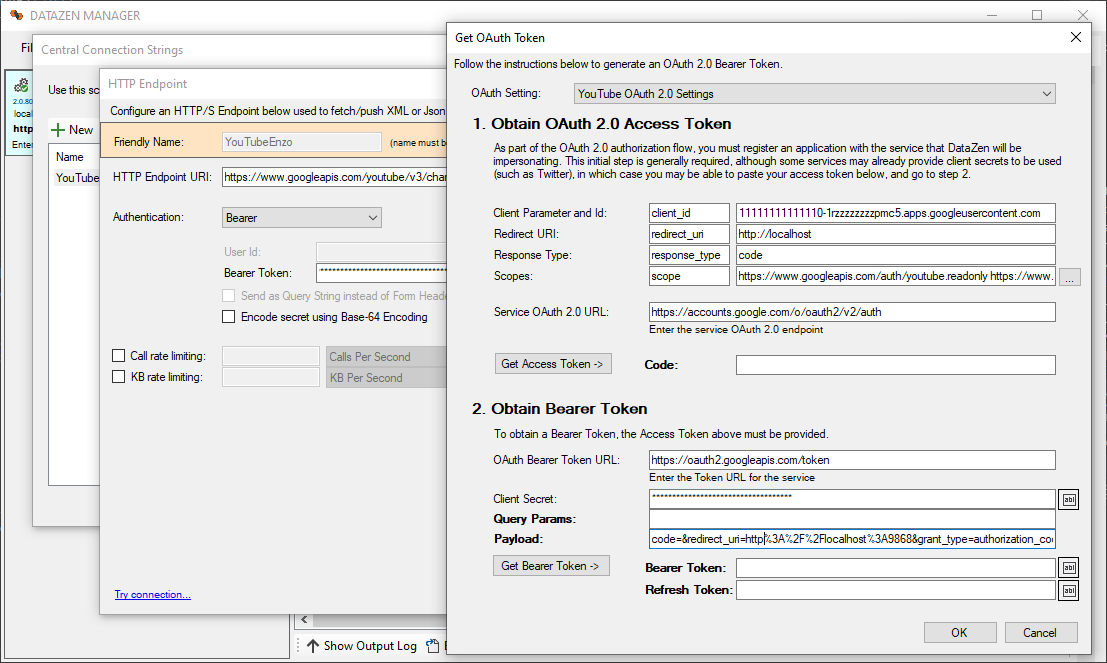
YouTube implements a complex 3-legged OAuth 2.0 authentication model that requires obtaining a Bearer Token and a Refresh Token.
Once this step is completed, DataZen can access any YouTube endpoint as long as the right scopes are added.
YouTube implements a Google OAuth 2.0 authentication flow. See how to create and configure a YouTube application with detailed configuration instructions
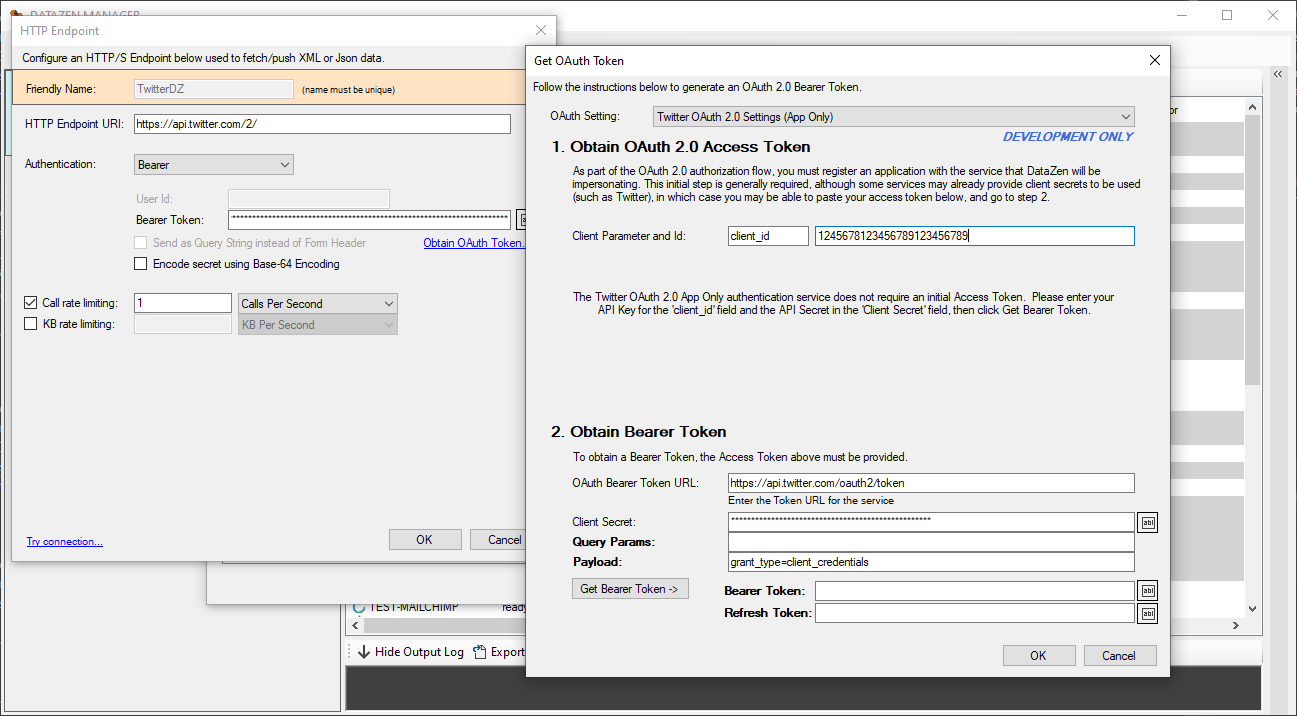
Twitter offers a simpler OAuth 2.0 model: its bearer tokens can be generated using DataZen, or directly
from the Twitter development portal. There are no refresh tokens or scopes needed.
See how to create and configure a Twitter application with detailed configuration instructions
LinkedIn requires a more advanced 3-legged authentication flow along with an approval process to access the
necessary Scopes so that DataZen can connect to the service endpoints.
See how to create and configure a LinkedIn application with detailed configuration instructions
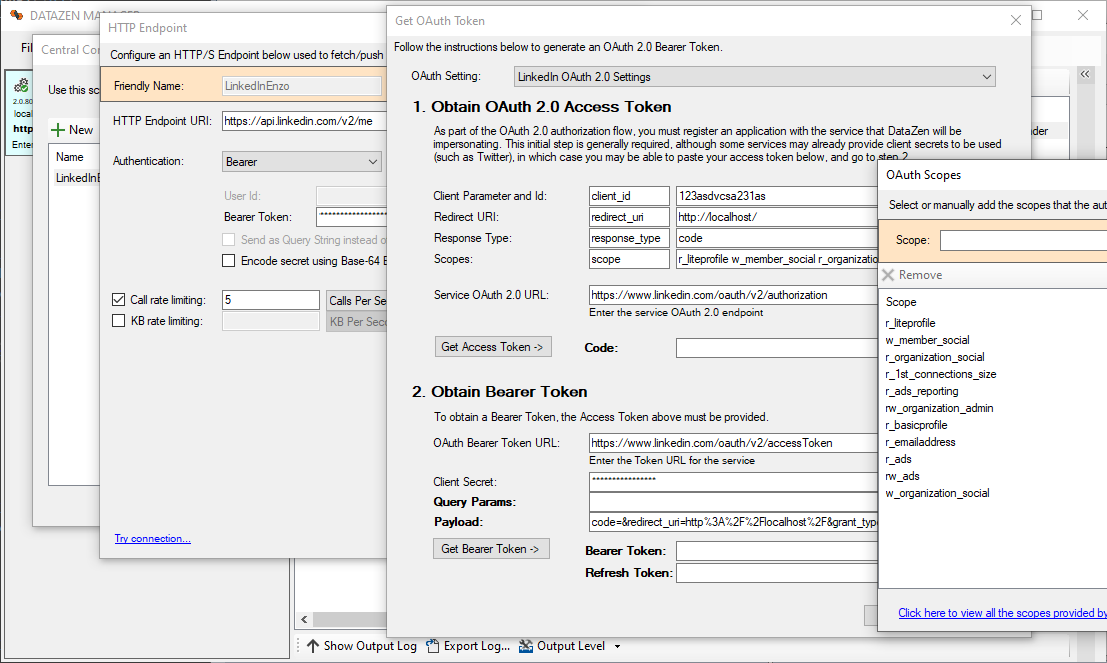
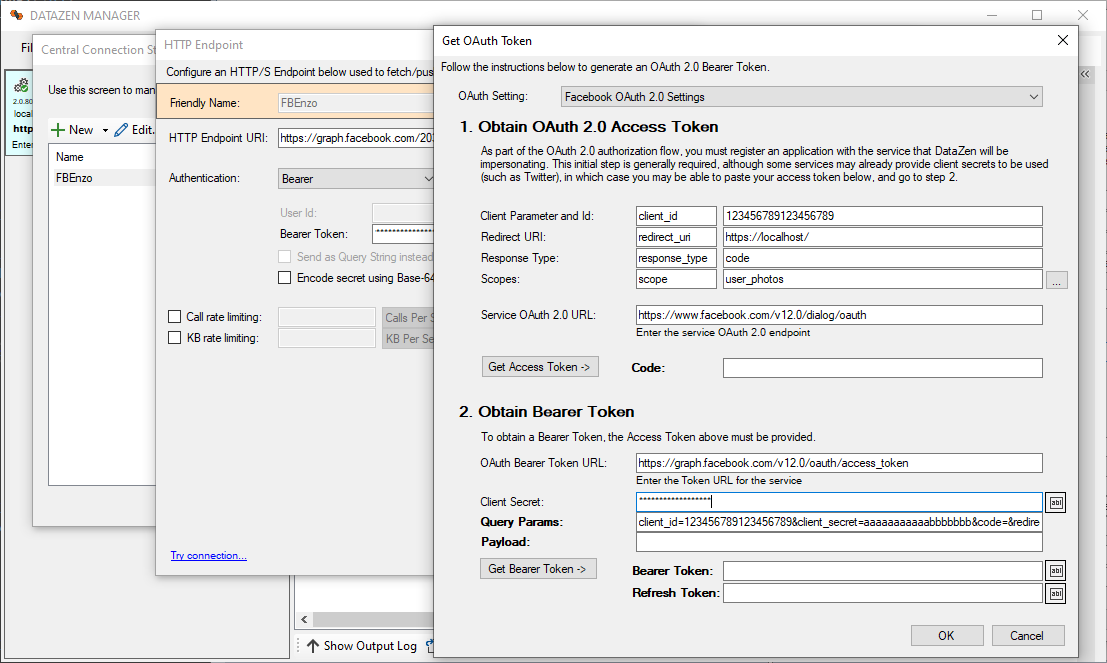
Facebook/Meta requires a more advanced 3-legged authentication flow along with an approval process to access the
necessary Scopes so that DataZen can connect to the service endpoints.
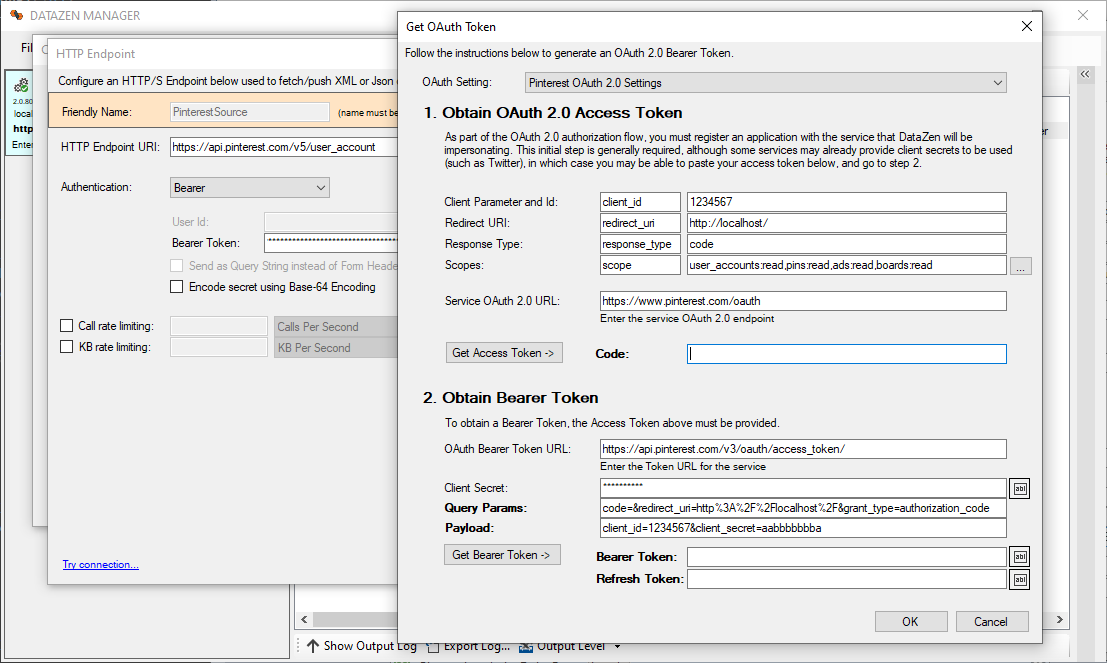
Pinterest requires a more advanced 3-legged authentication flow along with an approval process to access the
necessary Scopes so that DataZen can connect to the service endpoints.
DataZen supports virtually any form of OAuth 2.0 authentication including 2-legged and 3-legged. In addition, the configuration screen allows you to authenticate against services that implement other forms of authentication, if any, such as API Keys, Basic Authentication, and API Tokens.
In addition, DataZen can send the API Keys and Tokens as a URL Query Parameter or as a custom Header, and optionally encode the authentication header using Base64 encoding. This allows DataZen to support virtually any API REST endpoint that implements some form of authentication.
This blog shows you an example on how to configure social media feed using OAuth 2.0 settings; however, DataZen can connect to virtually any REST endpoint, including those that require refresh tokens, use Bearer tokens, API keys, and Basic authentication.
Once source and target connections have been defined, the hard part is out of the way. We can now configure a job that will monitor for social media feeds and forward them as a Parquet file into an Azure ADLS Storage blob. The job consists of two parts: a reader, and a writer. For more flexibility, and to enable multi-casting and replay options, you may want to create two separate jobs (a reader job, and a separate writer); however, for simplicity we will create a single job that performs both operations.
Let's start with the reader part of the job: reading Tweets.
A few things are going on here, so let's take a look:
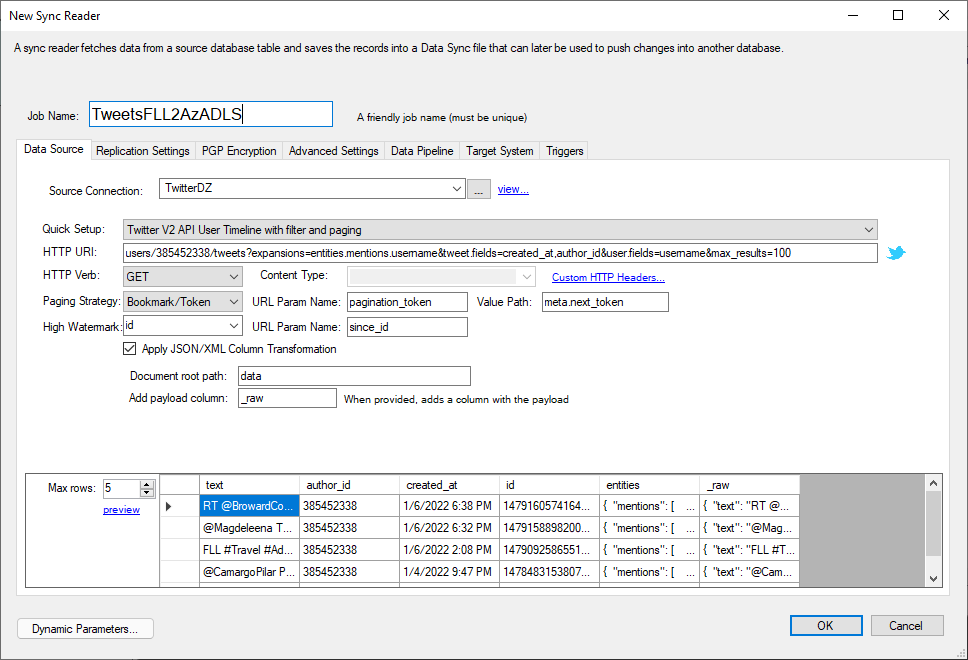
Clicking on the preview link calls the Twitter endpoint and performs the JSON transformation so we can inspect the data before
proceeding. This step is necessary to extract schema information dynamically from the REST endpoint.
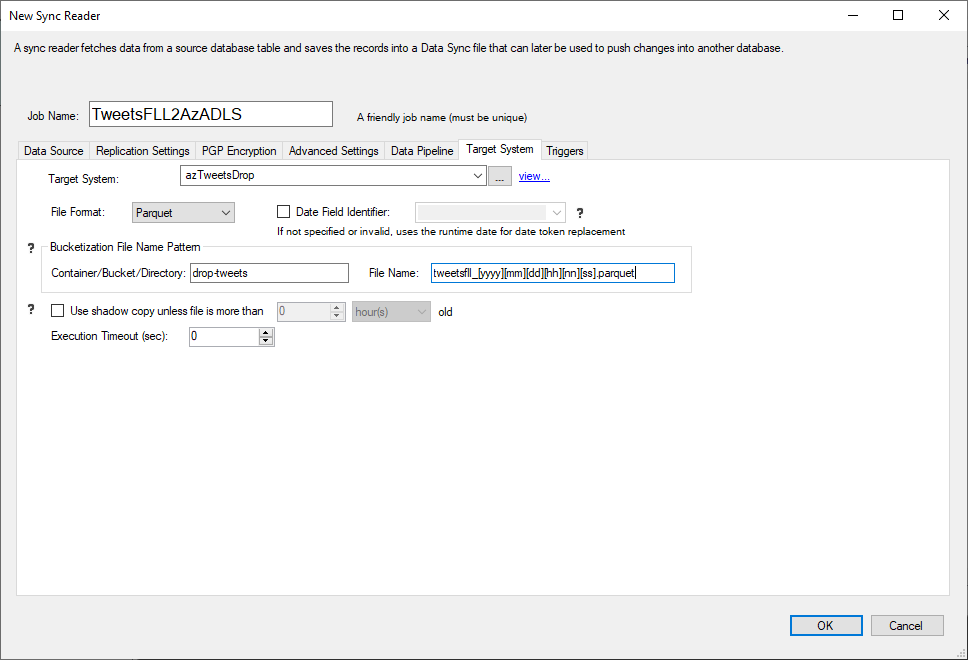
In this section we will configure the target an Azure ADLS blob container, stored in various formats. We can save Parquet, XML, JSON and CSV files. The naming convention of the file can offer a smart distribution of data across multiple files and containers based on date fields or any other value found in the source data set.
This screen shows how to configure a Parquet target file. The target connection is specified as an Azure connection to ADLS.
It could also be an FTP site or an AWS Bucket. The file name can use date tokens ([yyyy][mm][dd]) to create a dynamic name.
The container name could also contain date tokens. The container and file name could also contain source data field values to distribute
records into separate files using a deterministic approach.
Once the job has been created, we can run it manually or on a schedule. It can also be triggered using a DataZen HTTP Endpoint easily. When the job has completed, a Parquet file will be created in ADLS and ready for consumption by Azure DataFactory and/or Azure Synapse directly.
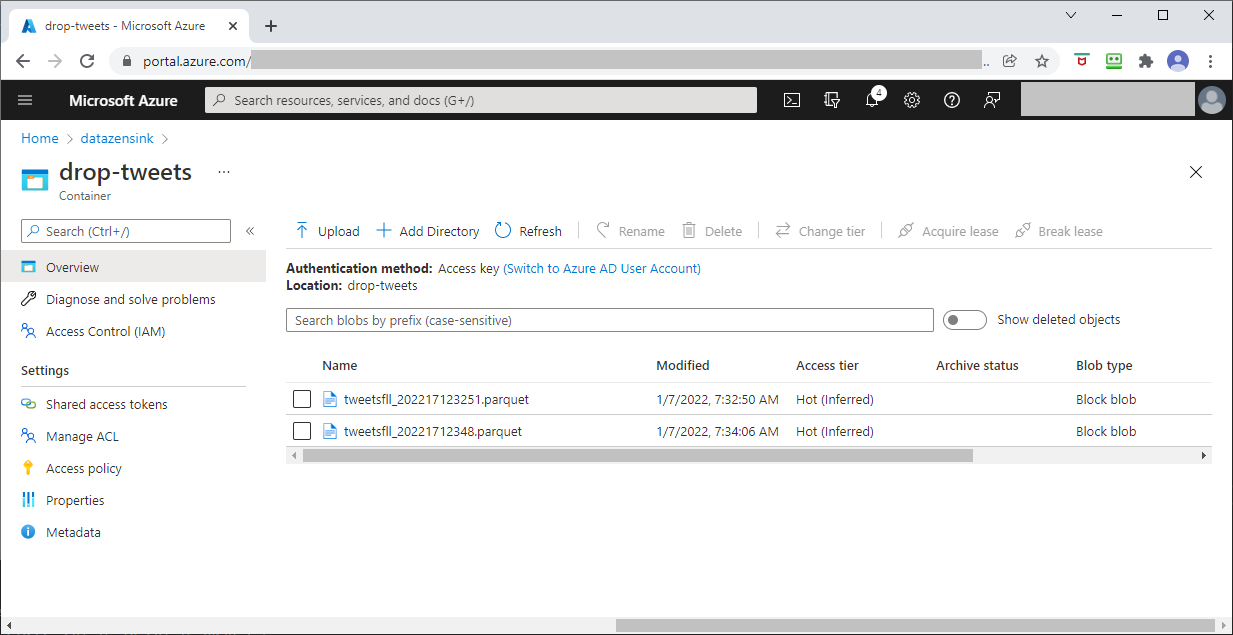
As we can see below using the Azure Portal, a couple of Parquet files have been created successfully and are available for reading in Azure Synapse.
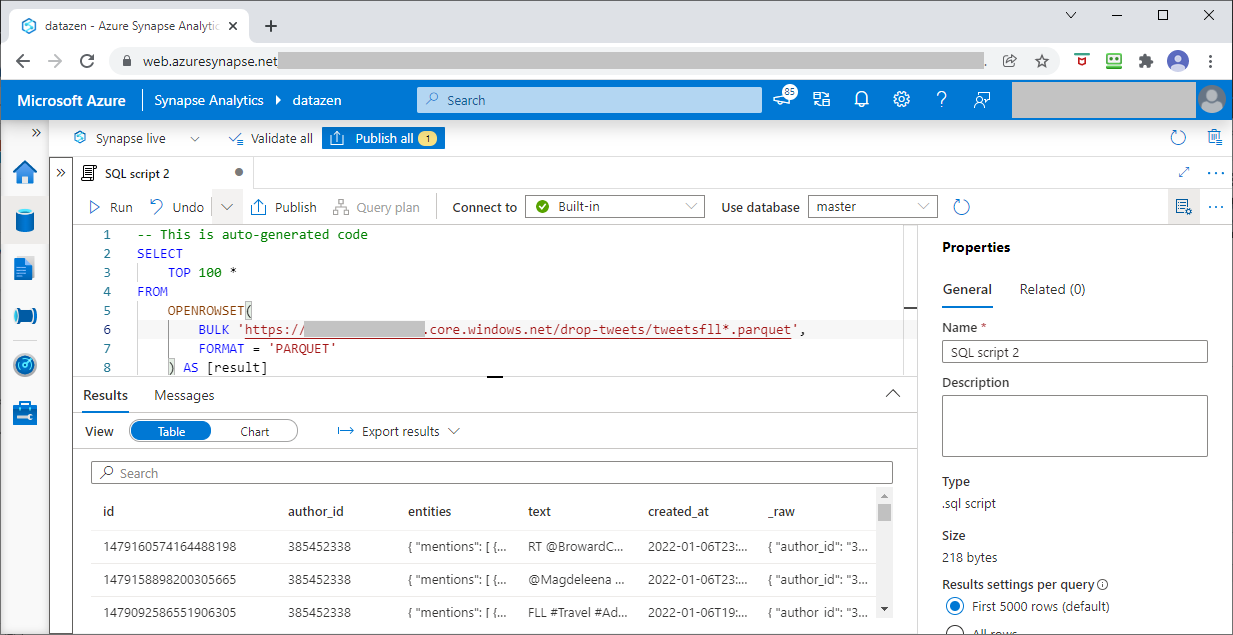
Now that the Parquet files are stored in Azure ADLS, we can leverage Azure Synapse to query these files easily and inspect their content.
Using simple configuration settings DataZen allows you to extract Social Media data quickly and forward the feeds into Parquet, XML, JSON or CSV files easily to an Azure ADLS Storage account for downstream processing such as Azure Data Factory and/or Azure Synapse queries. The flexibility of the OAuth authentication mechanism through DataZen allows you to configure the connections once and let DataZen manage authentication tokens using refresh tokens when provided by the service. Finally, the ability to configure and control call rates, paging, high watermarks and automatic JSON/XML to Data Set conversion gives you total control of your data extraction needs without writing a single line of code.
© 2025 - Enzo Unified