 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

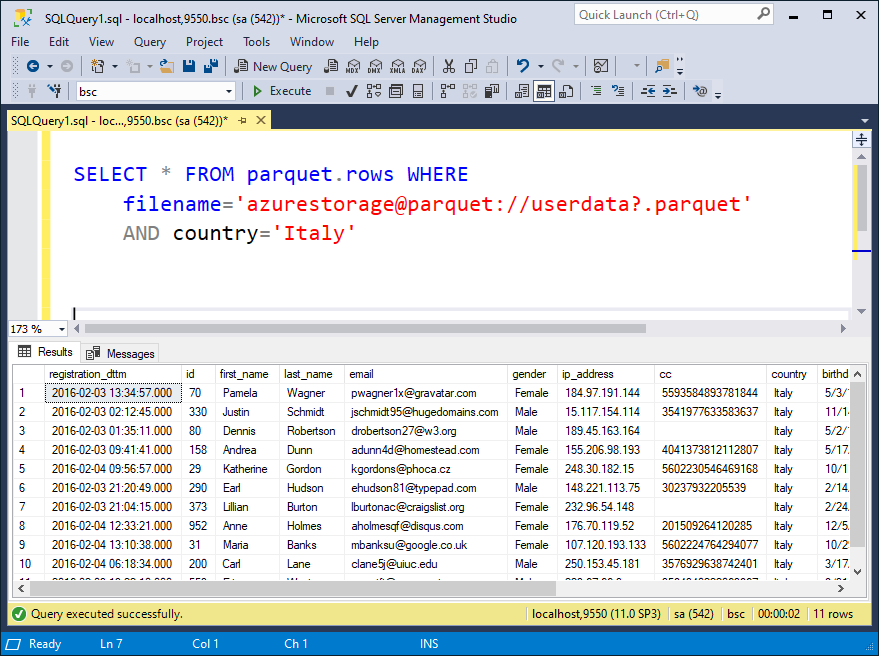
Query Parquet files directly from SQL Server Management Studio. Enzo Server is best for querying data sources ad-hoc and explore content directly within SQL Server Management Studio, in real-time.
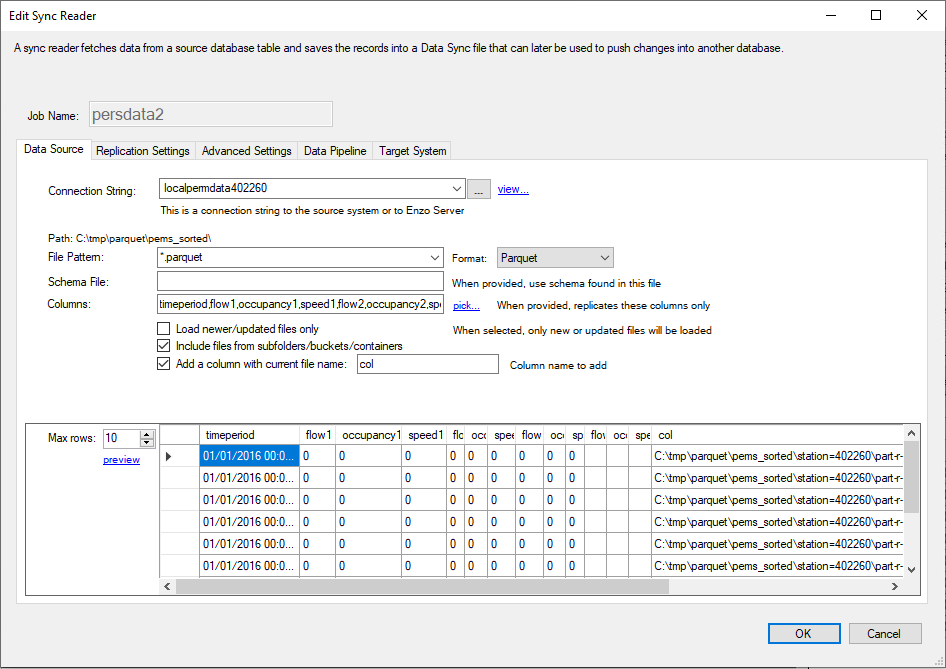
With DataZen you can read Parquet files to export data into other platforms, such as a relational database, other file formats, or automatically detect changes made to Parquet files and forward these changes into a messaging hub of your choice.
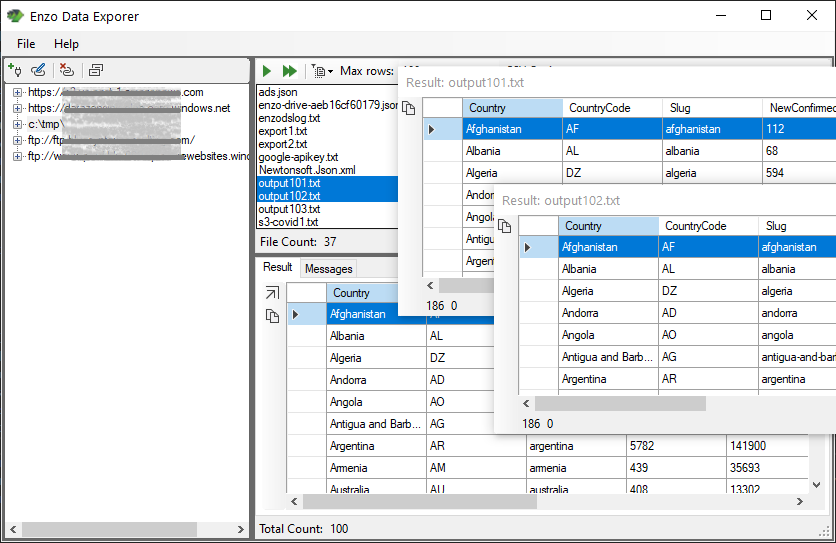
With Enzo Explorer, you can view the content of Parquet files located on your local machine, shared drive, FTP sites, or in the cloud (Azure Blobs/ADLS or AWS S3 buckets).
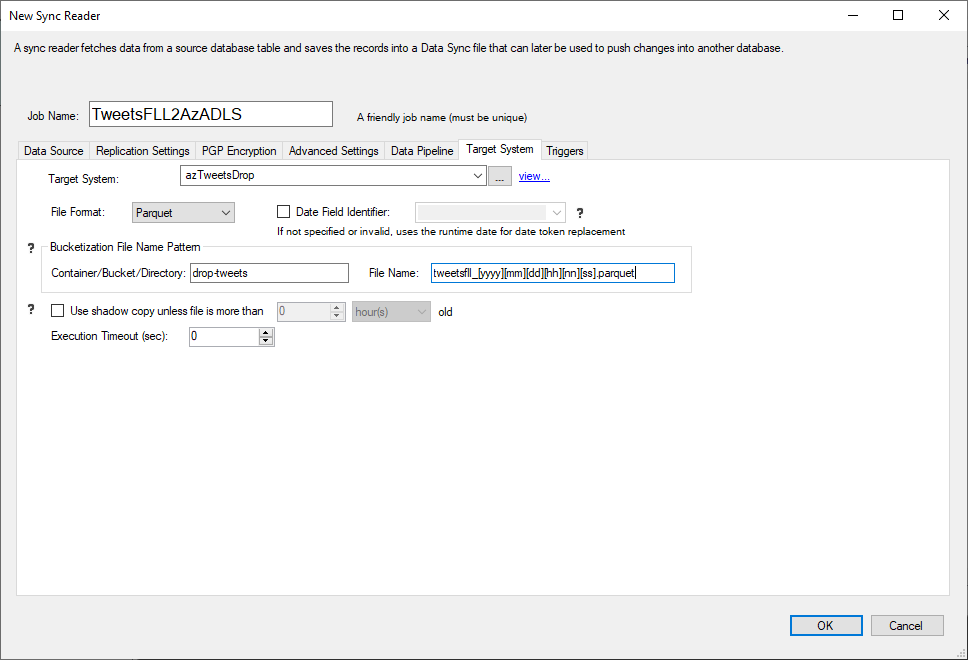
As a replication technology with built-in change detection, including content-based data distribution and support for schema drifting, creating or updating Parquet Files is best done with DataZen.
© 2025 - Enzo Unified