 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

In this blog we are going to demonstrate how to subset a MySQL table into a SQL Server database
using ENZO DataZen in order to improve report performance. Many reports execute complex
SQL commands against very large tables, which tend to slowdown over the years because of data growth.
However, since many reports do not need to pull records beyond the last two or three years, some organizations
are subsetting existing databases into a secondary database for reporting purposes, carrying only a few
years of information.
DataZen allows you to easily subset a database table from any source system into any target database, quickly allowing you to create smaller replicated databases. In addition, DataZen can automatically delete past data over the years so that your target reporting database only contains the number of reporting years desired.
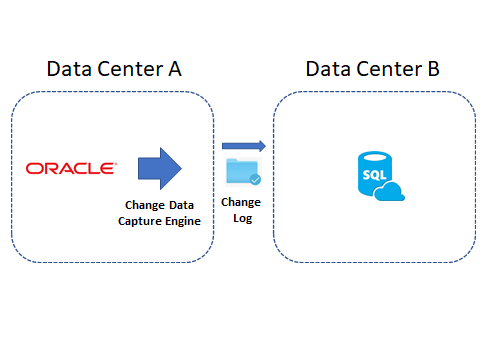
DataZen is a replication technology that can detect changes made to any source system through a proprietary
Change Data Capture (CDC) engine. Because the CDC engine built into DataZen is universal by design, it can
detect changes (adds, updates, and deletes) regardless of the source system (relational, no-sql, or any API exposed through ENZO Server
or an ODBC driver).
There are three kinds of Sync jobs in DataZen: Jobs Readers, Job Writers, and Direct Jobs.
ENZO DataZen replicates data using an eventual consistency model. This means that the data at the target system will eventually match data at the source.
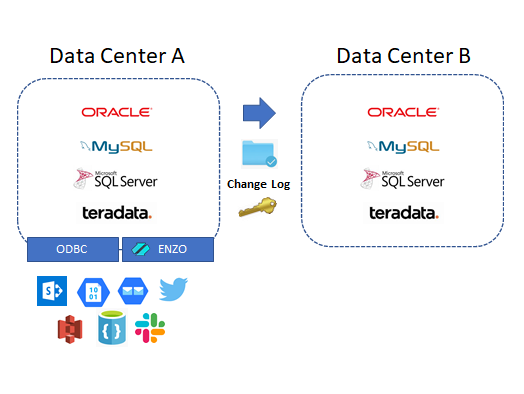
DataZen can natively connect to any relational database through an ODBC driver.
In addition, certain scripts can be automatically generated for some of
the well-known database platforms (Oracle, MySQL, Teradata, and SQL Server).
In addition to using ODBC drivers, DataZen can also access virtually any platform directly using
SQL commands through Enzo Server without the need for an ODBC driver. For example, if you currently
have ENZO Server configured to access SharePoint Online, you can instantly replicate SharePoint list data to any
other system with DataZen.
We will be using MySQL as the source system, and will demonstrate how to setup a Direct Job replication. As discussed previously, Direct Jobs combine both a Job Reader and a Job Writer into a single operation for simpler replication topologies. The SQL command used will select data from a MySQL table using a WHERE clause that automatically filters prior year data.
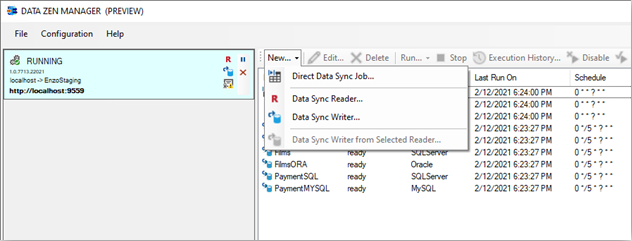
To create a Direct Job, start DataZen, click on the desired Agent (at least one agent must be registered),
and select NEW -> Direct Data Sync Job from the context menu.
Enter a Job Name, and specify a connection string to the source system. You can click on build...
to help construct a valid connection string. Enter the SQL statement below for MySQL and click on
preview. In this example, we will select records from the sakila.customer table,
which is a sample database available in MySQL.
SELECT * FROM sakila.customer WHERE year(last_update) >= year(now()) - 1
The WHERE clause provided will select the records that were modified within the last two years. This technique allows you to leverage the power of the SQL language to choose the desired timeframe window and add other conditions based on your objectives.
If the above command returns 0 records, you may need to manually update the last_update field in the sakila.customer table so that the above SELECT operation returns data.

As years pass, the SELECT operation will automatically filter out the prior years; DataZen can treat the missing records as being deleted by checking the "Identify and Propagate Deleted Records" checkbox in the Replication Settings tab.
Click on the Replication Settings tab and select customer_id,
which is the key field in the sakila.customer table.
Because we want DataZen to automatically remove prior year records, check the
Identify and propagate deleted records and leave the default heuristic method option.
For improved performance, select the last_update field as the Timestamp column.
Note that the last_update field is used both as the filtering mechanism that feeds the subset database, and the field that limits how many records are retrieved on a daily basis.
Choose a replication schedule (as a Cron expression), and select a folder in which the Sync files will be created.

Click on the Target System tab and specify a connection string. In this example, we are using a SQL Server Native connection; as a result the High Performance MERGE Operation option is available (this operation offers signficant performance advantages for SQL Server).
In this example we are specifying the following table name:[mysql].[customer].

To minimize any errors in the creation of the target table, including possible data type convertion issues, click on the View/Run Table Script button. A screen will allow you to review the SQL command used to create the target table and execute the command that will create the target table. Enzo will automatically select the correct data type for the selected target system.
Click on Execute Command Now to create or recreate the target table.
Click Close and then click OK to create the Direct Job.

If you have selected a Schedule (Cron Expression) the job will start immediately; otherwise you will need to click on the Start icon for the job. The example provided selects records from a small table in Oracle (107 records in all), so the complete operation takes just a few seconds.
You can see the details of the operation (read and write) from the Output Log at the bottom of the screen.

Now that the replication job has been setup the following will take place automatically:
This blog shows you how you can build a Database Subset using DataZen and replicate a portion of
a database table to a secondary database for reporting and analytics purposes, with automatic
record purging over time. The ability to filter source records, and further limit replication
by using a timestamp allows you to build an efficient replication mechanism between various
database platforms.
To try DataZen at no charge,
download the latest edition of DataZen on our website.
Integrate data from virtually any source system to any platform.
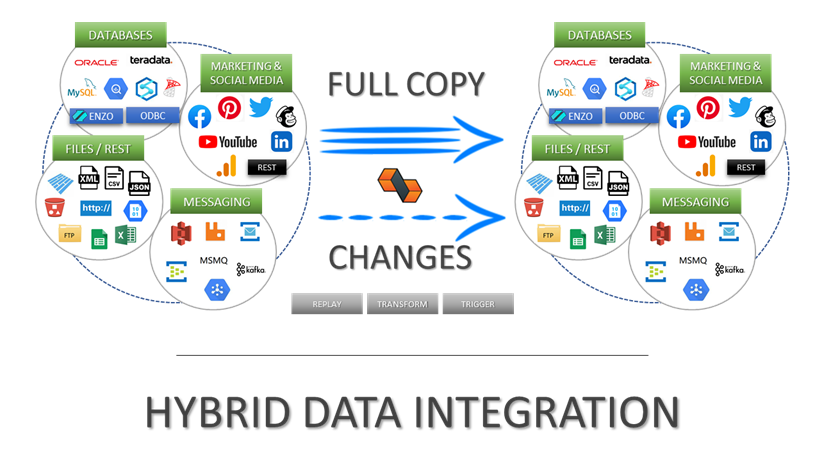
Support for High Watermarks and fully automated Change Data Capture on any source system.
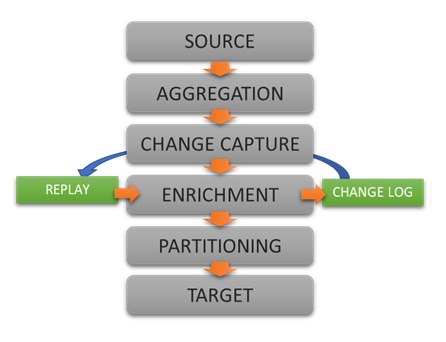
Extract, enrich, and ingest data without writing a single line of code.
To learn more about configuration options, and to learn about the capabilities of DataZen,
download the User Guide now.
© 2025 - Enzo Unified