 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

This blog provides an overview of Data Pipelines in Enzo DataZen, with a focus on data masking and hashing. Data masking
and hashing allows organizations to build or refresh lower environments by copying production data, while protecting sensitive
information for compliance or security reasons.
Scenarios
With DataZen and data pipelines you can implement the following scenarios:
For example, you can easily implement the following data refresh lifecycle with DataZen using data pipelines: production data stored in Oracle is refreshed on a periodic basis to the Staging environment with an initial data masking of highly sensitive data and filtering executive pay records. The Quality Assurance environment obtains a further masked set of data, with even fewer records. Finally, the R&D environment uses a minimal set of masked records from production data, but requires the information on other platforms for integration purposes, such as Teradata and MySQL.
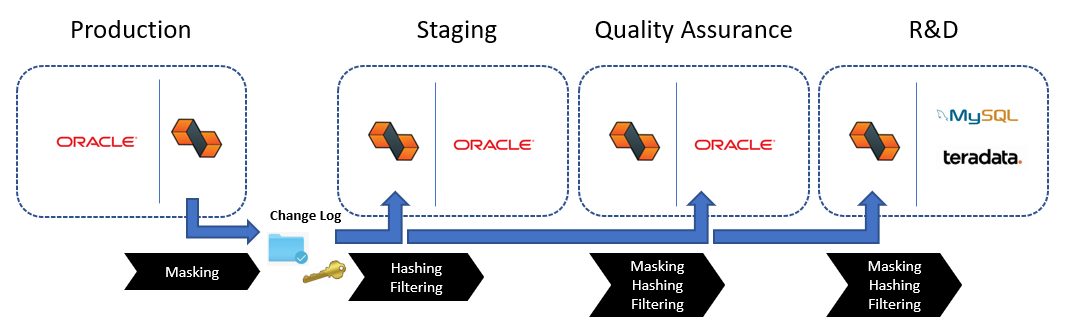
DataZen allows cross database replication, from any source to any target. Data masking and hashing takes place during the replication process, either while reading from the source system, and/or before applying changes to the target system.
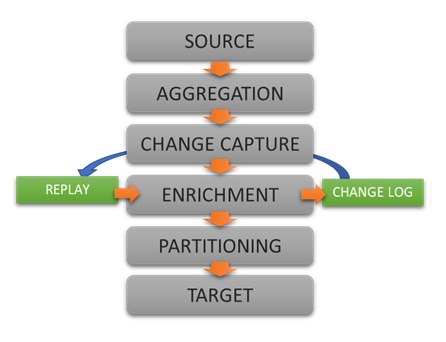
DataZen implements the concept of a data pipeline for its replication jobs. The data pipeline feature of DataZen is a data processing engine through which data flows and may be modified as desired. Four components are available in a data pipeline: Data Filter, Data Hashing, Data Masking and Data Quality. You can combine any number of components in each replication job, and choose the order of execution of each component.
Data Filtering
Applies a secondary filter to the data by adding a SQL Where clause as a Data Filter. This can be useful when the data source doesn’t support a full SQL syntax, or when filtering needs to occur after hashing or masking has occurred.
Data HashingApplies a hash algorithm to a selected data column (must be a string data type); supported hashing algorithms are MD5, SHA1, SHA256, SHA384 and SHA512.
Data MaskingApplies masking logic to a selected data column, such as credit card number or a phone number. Supports generating random numbers, free-form masking, and generic / full masking.
Data QualityValidates simple rules against a data column and throws a warning or an error if the data doesn’t match the specified rules.
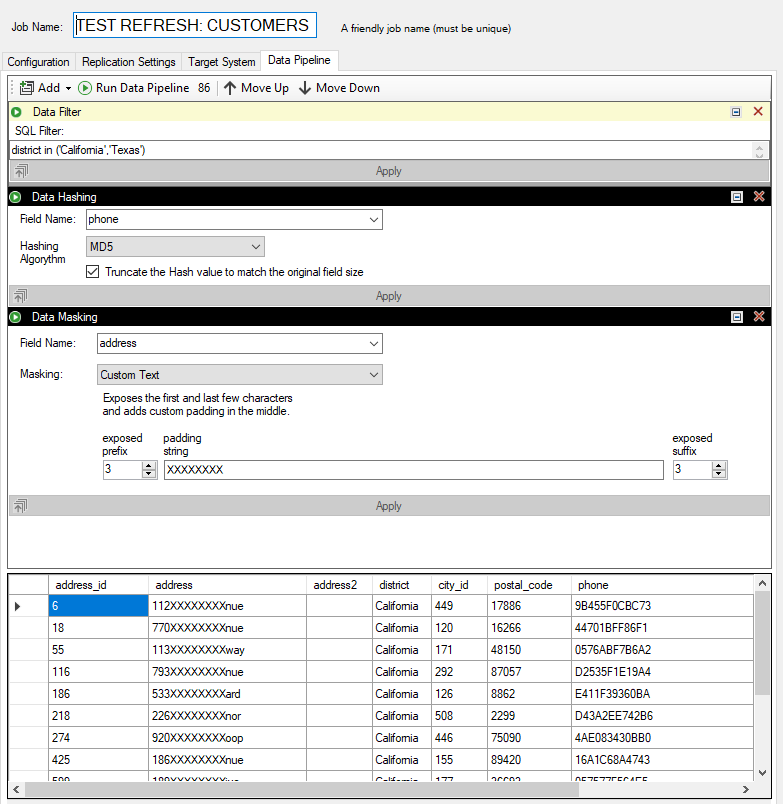
Hashing phone numbers, and masking addresses with a data pipeline
To ensure sensitive data is protected data pipelines offer two components for modifying data before replication takes place: data masking, and data hashing.
Masking data takes place by transforming the original value to a non-identifiable output. Generally speaking, data masking does not attempt to generate an output that is unique in nature; if uniqueness needs to be kept, see Data Hashing. Five data masking options are available:
Default – replaces a string field with the character X; replaces a numeric field with 0; replaces a date field with 1900-01-01 and NULL for other data types
Credit Card – Exposes the last 4 digits of the credit card and replaces all other characters with X
Email – Exposes the first character, and replaces the remainder with XXX@XXX.com
Random Number – Replaces a numeric field with a random value based on the data type
Custom String – Exposes the first few and last characters, as desired, and places a constant string in the middle as provided
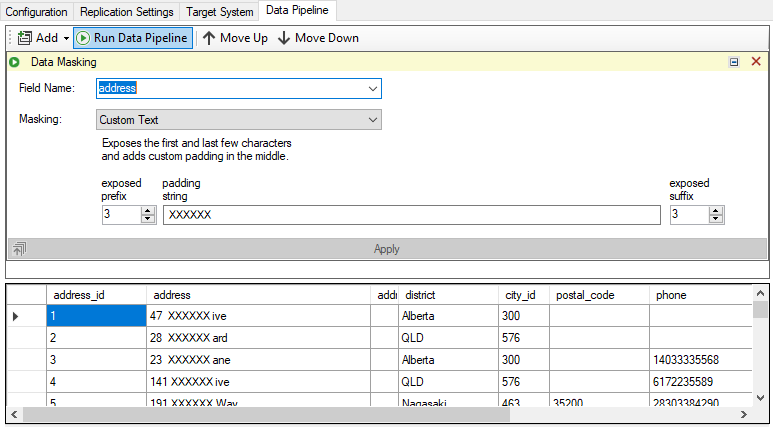
Masking the address field with custom transformation
Hashing data is also a data transformation mechanism, in which the source column is considered sensitive, but should be
modified in a way that each hash is unique and consistent for a given input. For example, a Social Security number may
be a good candidate for hashing: every hash value will be unique given the original SSN, and will not change with future
replications taking place as long as the source SSN hasn't changed.
Hashing allows organizations to implement testing routines on known records without knowing the actual value of the
production record. For example, the phone number '28303384290' will be hashed as '9A091F5CC202E565F72C17F2D84C6042'
using an MD5 algorithm. As long as the phone number doesn't change, the hash value will always be the same.
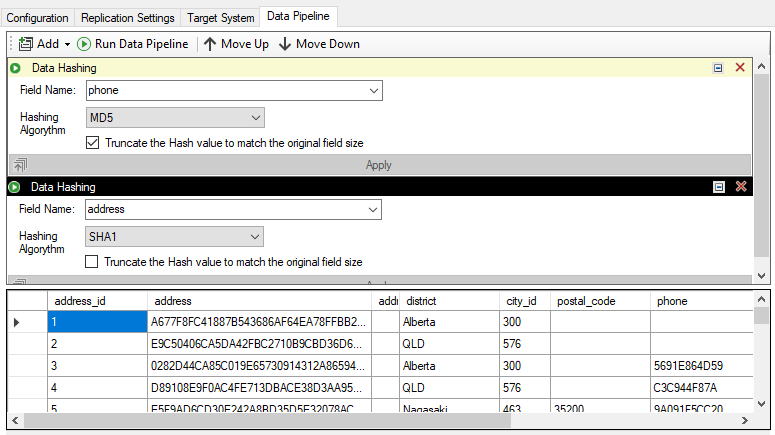
Hashing two sensitive fields: phone numbers and addresses
In this blog, we reviewed how DataZen implements data masking and data hashing as part of its replication topology, regardless of the source or target system. This capability allows organizations to implement data de-identification for lower environments, such as dev/test databases, and sharing partial information with business partners.
Integrate data from virtually any source system to any platform.
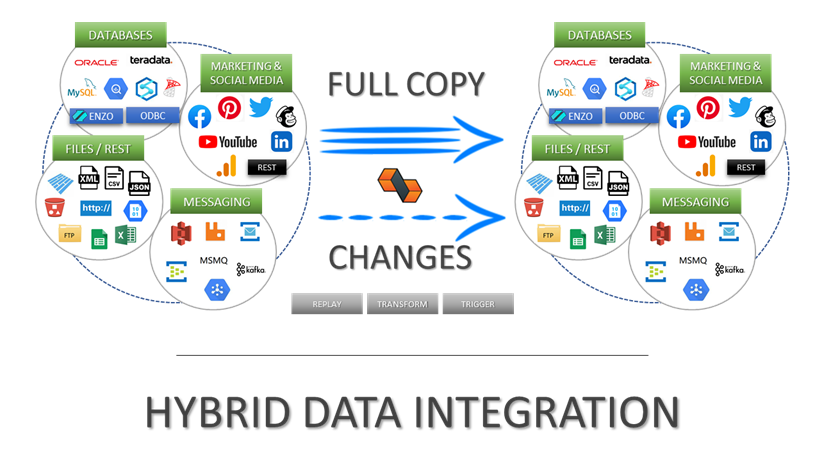
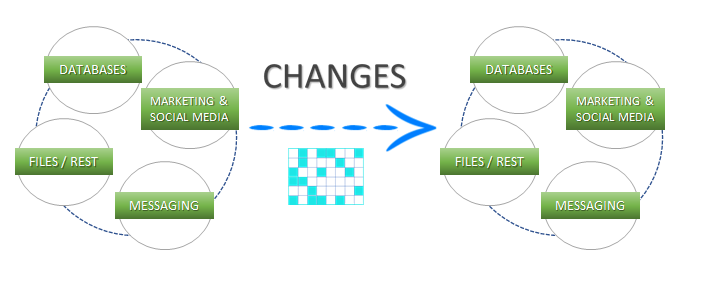
Support for High Watermarks and fully automated Change Data Capture on any source system.
Extract, enrich, and ingest data without writing a single line of code.
To learn more about configuration options, and to learn about the capabilities of DataZen,
download the User Guide now.
© 2025 - Enzo Unified