 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

Businesses managing remote sites face key data management decisions affecting their ability to extract meaningful information in a timely manner. This is particularly important for companies with sites that are difficult to access, with spotty connectivity, or with security or business requirements that enforce network isolation. Industries that face these challenges include the energy sector (both traditional and renewable), utilities, retail locations, transportation, property management, cities, and even business entities such as franchisees and holdings.
This article discusses the two data replication models typically used when replication data from remote sites: push and pull replication. Regardless of the replication model used, the need to implement data replication to a cloud data hub is driven by the desire to enable key business and technology capabilities such as cloud analytics, application integration, Artificial Intelligence (AI) & Machine Learning (ML), and operational dashboards.
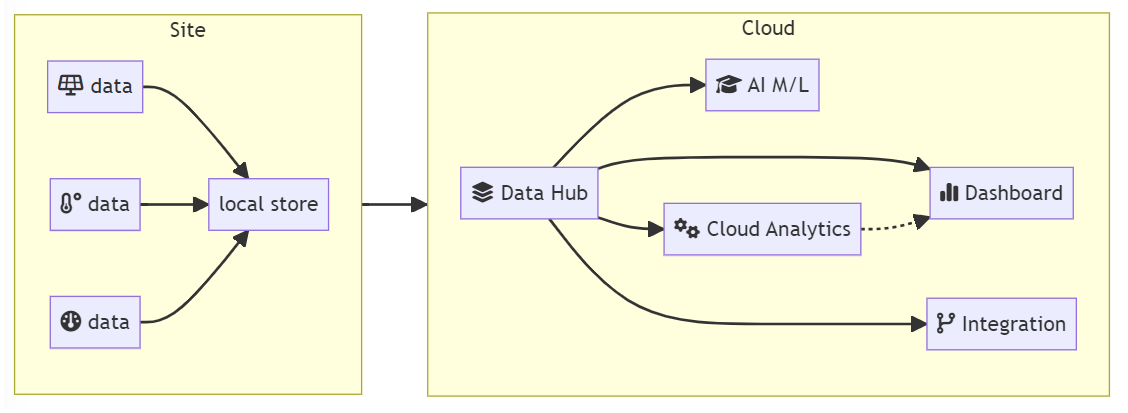
Remote Data Replication: the need for a data hub
Dealing with multiple remote sites can quickly become a complex architectural decision, specifically when
trying to optimize how to best centralize
data assets in a highly resilient manner.
The implications of choosing push or pull replication can be significant in terms of
timeline, scope, security, and even feasibility. In addition, security or network isolation requirements can have
a strong impact on the approach, and a hybrid implementation may make sense in some cases.
From a data architecture standpoint, the push replication pattern favors a hub-like centralization of aggregated data,
fully decoupling the sending and receiving of information, which uses a shared-nothing paradigm.
In contrast, the pull replication pattern tends to introduce a "central brain" model that relies on orchestration, which
implies the need to design, build, and manage a central component (that we will call the "controller" in this article).
The pull model, by design, requires a controller that needs to be aware of the sites it controls
and must keep other site-specific data. Because this pattern requires a custom-built centralize
controller, it can also be referred to as a central-brain design.
A remote proxy (represented as the PULL rectangle below) is usually necessary. This is typically
a virtual machine that hosts a proxy that the controller can access remotely.
One of the primary advantage of this model is that the data hub (shown as a data lake below) can be changed
without having to reconfigure any of the remote sites. However, this model usually requires the development of
custom orchestration logic and is typically harder to deploy and scale. In addition, because the controller needs
to connect to the pull proxy, additional security requirements may apply.
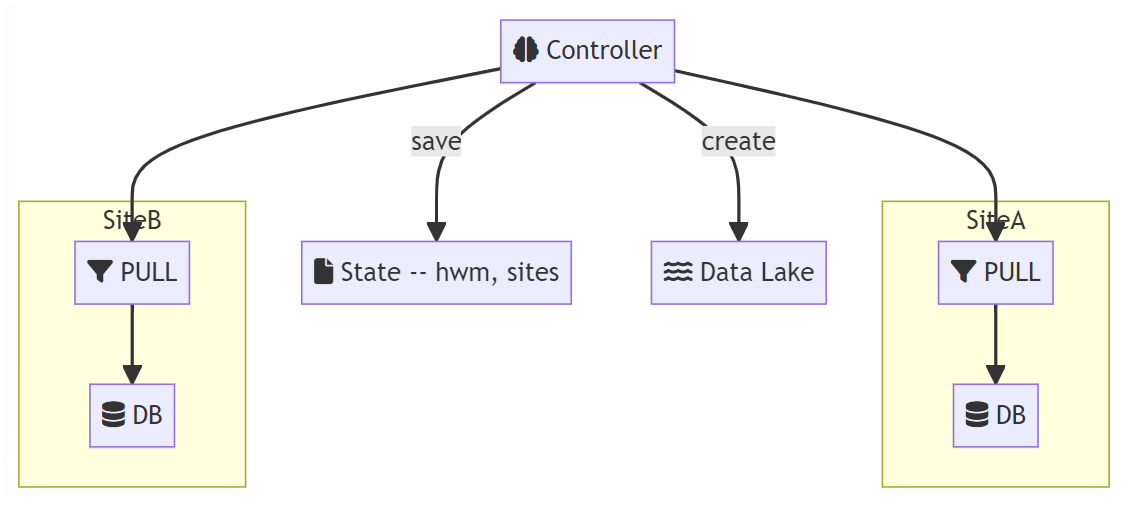
Pull Pattern: the central-brain orchestration model using a controller
hwm: high watermark
The push model sends data as soon as it can without requiring a controller.
In this model, data replication software is usually needed (represented as the PUSH
rectangle).
One the primary advantage of this model is a fully decoupled architecture, making it easier to add sites
without affecting downstream systems. Another advantage is
the ability to perform decentralized data shaping on the remote sites, such as file formatting or data masking.
This helps offloading processing power to the virtual machines located on the remote sites.
However, once a target type has been configured (shown below as a data lake for example), it can be harder
to reconfigure later depending on the push technology capabilities. The choice of the target may not matter as much
when pushing files in a data lake, since these files can further be processed to another secondary target.
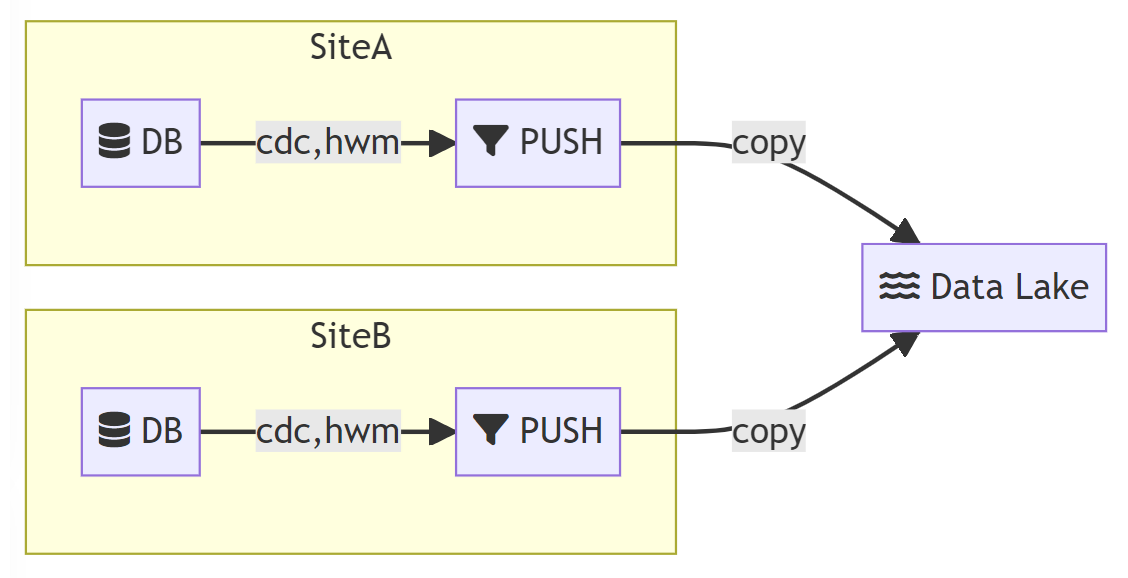
Push Pattern: the fully decoupled hub model
cdc: change data capture
hwm: high watermark
Selecting the right replication model usually comes down to a cost question: how much will it cost to build/buy, deploy, and maintain the environment? Calculating your Total Cost of Ownership (TCO) of pushing or pulling data may help in this decision-making process. However, there may be overriding constraints that would limit your choice, specifically security and compliance. If accessing your remote sites directly from a central location (using a cloud-based controller) is not possible or permitted, the push model may be the only option available.
When both options are available, push replication will usually offer the benefits of a shared-nothing
architecture without having to build and manage a controller in the cloud. However, the acquisition
cost of the push technology may offset the cost to build. Once again, the TCO analysis will be
your best bet to ensure your overall integration costs are understood.
Finally, it should be noted that choosing one model versus the other is rarely a
business decision because both can deliver the same capabilities
in terms of supporting your cloud analytics, AI/ML scenarios, integration and dashboards objectives.
Enzo Unified is a leader in data virtualization, any-to-any data replication, and data integration. If you are interested in better understanding your data replication options, contact us at info@enzounified.com.
© 2025 - Enzo Unified