 PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰

DataZen allows you to integrate all your data in a single platform you can host on your Virtual Machines, or in the cloud. With DataZen,
you can connect to hundreds
of applications, HTTP REST API endpoints, CRM/ERP/HR platforms, relational databases, flat files (including Parquet files) and messaging hubs
quickly without complex design surfaces. Finally, DataZen makes it easy to publish data to cloud Data Lakes, including AWS S3 and
Azure ADLS / Blob storage so you can further leverage existing cloud-based ETL platforms seamlessly.
Modern integration architectures favor an integration pattern called "Dumb Pipe, Smart Endpoint", which is a Microservice Architecture Pattern (also called ELT in the data integration world, as opposed to ETL - Extract, Transform, Load) in which the "Transformation" of data happens at the target system. The ELT pattern is favored in the data integration space because traditional ETL workflows are significantly more complex to maintain and make the data less reusable when it is modified as part of the data ingestion process. For example, SQL Server Integration Services (SSIS) packages and BizTalk Orchestrations are notoriously hard to maintain and require highly specialized skills when the data flows need to be modified.
DataZen offers a simple yet powerful data ingestion pipeline that follows the Dumb Pipe, Smart Endpoint architecture pattern.
The data ingestion pipeline first reads data from any source system, including any database platform, ODBC driver, HTTP/S REST API
endpoint, flat file, Parquet file, or individual messages from virtually any messaging platform (Kafka, MSMQ, RabbitMQ, EventHub...).
DataZen follows an ingestion process that provides data aggregation, data change filtering, data enrichment,
and data partitioning before it is sent to its target.
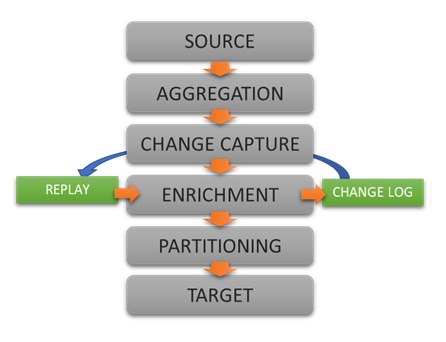
DataZen Data Ingestion Pipeline Overview
Let's take a deeper look at DataZen's ingestion engine.
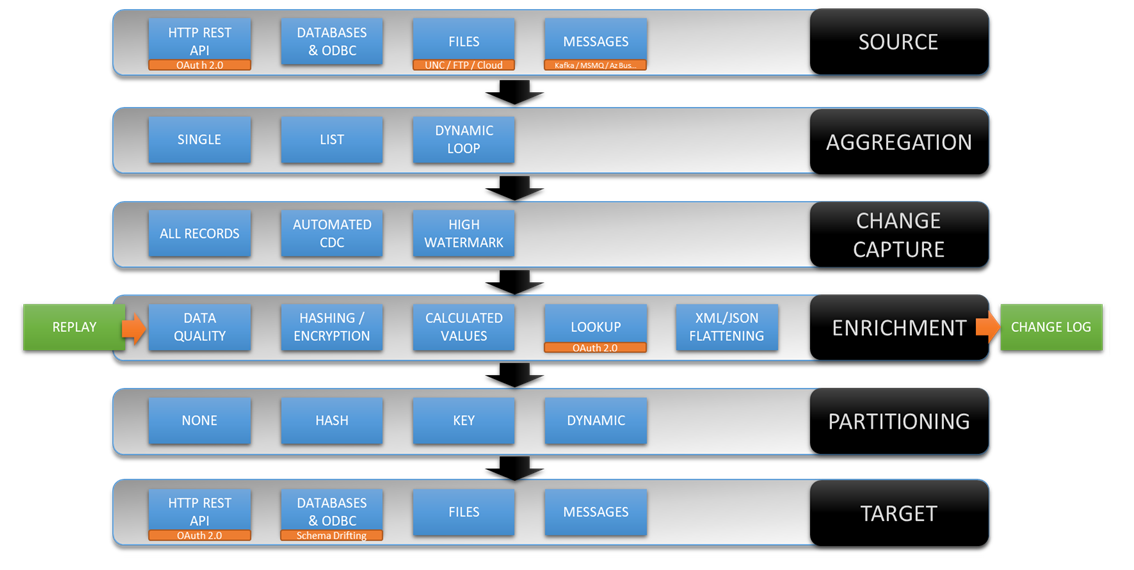
DataZen Ingestion Pipeline
DataZen can ingest data from virtually any source system, including HTTP/S REST APIs, relational databases, ODBC drivers,
flat files (JSON/XML/CSV and Parquet) stored on FTP sites/UNC Paths/Azure ADLS/AWS S3 Buckets, and messaging platforms
(including the Azure EventHub, Azure Bus, AWS SQS, RabbitMQ, MSMQ, Kafka and Google PubSub).
Since DataZen also supports Enzo Server and ODBC drivers, DataZen can ingest data from hundreds of data sources.
HTTP/S REST API data sources include support for various authentication schemes, including OAuth 2.0 and automatic
Refresh Tokens renewals that many modern APIs require. DataZen supports virtually any HTTP REST API service including
Twitter, YouTube, Facebook, LinkedIn, SEMRush, Ceridian Dayforce, MS Dynamics, SalesForce and many other. In addition,
DataZen supports various HTTP paging methods that some HTTP REST APIs require.
Most data sources offer an aggregation mechanism. For example, you may need to ingest 100 Parquet files in a single operation (using a list of files based on a wildcard search for example), or call an HTTP/S endpoint in a loop for 50 individual IDs or Account Numbers and treat the output as a single data set before proceeding to the next phase in the ingestion engine. When the source is a queuing system, you can choose to group individual messages in a time window and send the payload as a data set.
The Change Capture layer of the ingestion engine allows you to identify which records should be ignored.
Two options are available and can be used jointly: High Watermark tracking, and Automated Change Data Capture (CDC).
A High Watermark value is a pointer (such as a date) that is later used as a starting point for detecting changes
in a source system, including from HTTP/S REST API endpoints.
In addition, DataZen can also detect changes through an internal differential
engine that automatically identifies which records were created, modified, or deleted -- regardless of the source
system. This allows DataZen to implement a CDC mechanism transparently on any source system, even if the source
system doesn't natively provide a change capture mechanism.
Enrichment is a form of "Transformation" that is meant to modify the selected data only when absolutely necessary or to
add calculated fields that are not originally part of the source system but considered essential to the output. This phase
also includes the ability to flatten JSON/XML documents into rows and columns automatically, perform HTTP/S lookups, and
hash or mask the data before it is saved for security reasons.
In some cases, the data should be partitioned using a desired distribution pattern before the data should be sent to the target system. Partitioning options include hashing, key value, and dynamically calculated based on the content of the data itself. For example, you may decide to partition the data by Country Code so that each file created contains information specific to a single country, or create a database table per Customer ID.
The target system can be virtually any platform including all those identified in the Source System section. Because DataZen manages the schema of the data automatically, you can send the output to any target system regardless of where the data came from. For example, you can easily send Parquet files into a database table, or vice-versa. You could just as easily configure DataZen to automatically detect changes in a database table and send corresponding messages in a queue.
DataZen offers an easy-to-use hybrid data ingestion engine through a flexible, code-free architecture that follows the "Dumb Pipe, Smart Endpoint" principle through its powerful data ingestion pipeline, and supports hundreds of source and target systems including HTTP REST API endpoints, CRM/ERP/HR platforms, relational databases, flat files (including Parquet files) and messaging hubs.
© 2025 - Enzo Unified