PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰
PLATFORMS
SOLUTIONS
BLOGS
CONTACT
☰


In this post we are looking at ways to quickly import CSV data (flat files) into SQL Server and how to automatically create target tables when they don’t exist.
In a previous blog post we discussed how to explore and read CSV data using SQL commands; this post builds on the previous topic and focuses on data ingestion into the SQL Server database platform; the samples provided will work with SQL Server 2012 and higher.
We will be using some of the sample data from a previous blog post that shows arrivals for flight into the Miami and Fort Lauderdale airports (the data was extracted from the FlightAware adapter and saved as a CSV file).
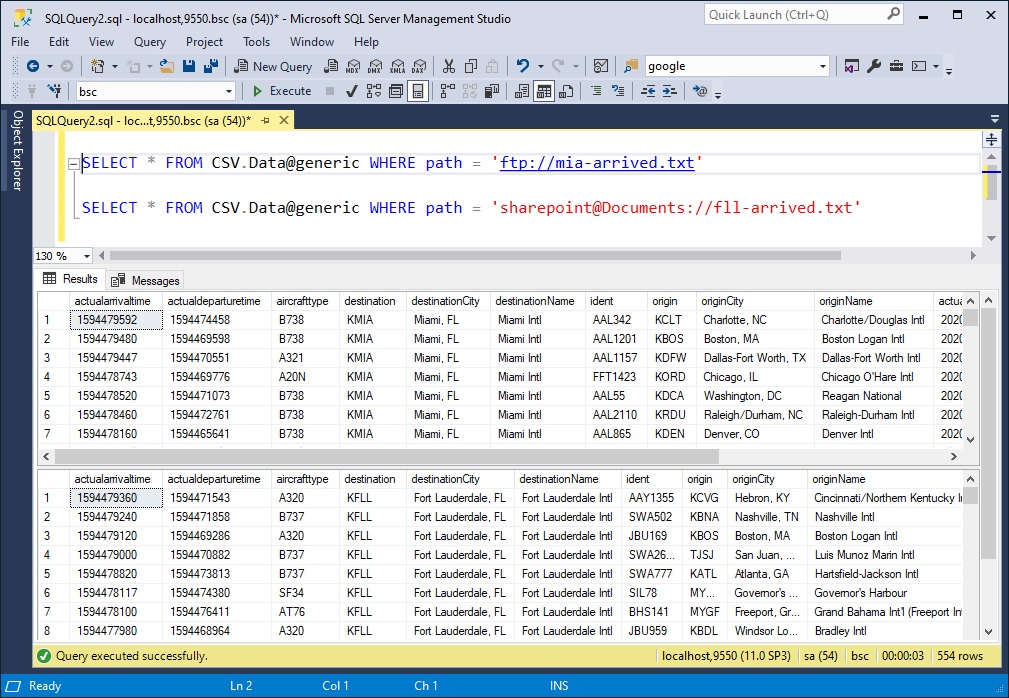
We will be importing this data into a SQL Server table shortly. Notice the simplicity of the SQL syntax to query data from two entirely different systems: SharePoint Online and an FTP server. Going forward we will be using this SQL command to import data:
SELECT * FROM CSV.Data@generic WHERE path = 'ftp://mia-arrived.txt'
Importing data into SQL Server requires the use of the SQLServer adapter. This adapter offers important capabilities that facilitate data synchronization between the SQL Server database platform and external data sources. We will be using the PumpBulk handler on this adapter to import data into SQL Server; but first, let’s configure a couple of connection strings so we can use it.
The PumpBulk handler does not require a configuration setting to be created for the SQL Server adapter; however, it does require setting up two database connection strings: one against Enzo itself (also referred to as the loopback connection), and the database connection where the target table will reside.
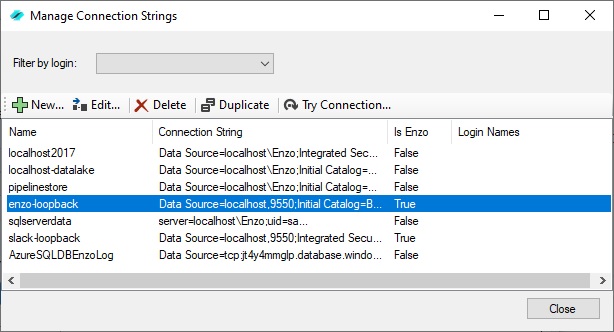
Connection Strings are managed in Enzo Manager and are stored with strong encryption cyphers.
You can use the Login Names field to control access based on the logged in user.
To create a new connection string, click on the New button. Make sure to create a connection that connects to Enzo (the Is Enzo property will display True to indicate the connection points to an Enzo server). In my example I will be using the enzo-loopback (which points to Enzo) and localhost-datalake connection strings (which points to my local SQL Server database).
The first method to import CSV data into SQL Server is to call the PumpBulk operation directly using
an SQL command. This operation takes at a minimum four parameters: the Enzo connection, the target
database connection, the SQL command to execute against Enzo, and the destination database
table (two or three-named part).
exec SQLServer.PumpBulk 'enzo-loopback', -- enzo connection 'localhost2017', -- target database connection 'SELECT * FROM CSV.Data@generic WHERE path = ''ftp://mia-arrived.txt''', -- SQL Read '[DataLakeDev].[FLIGHT].[ARRIVED]' -- target database table
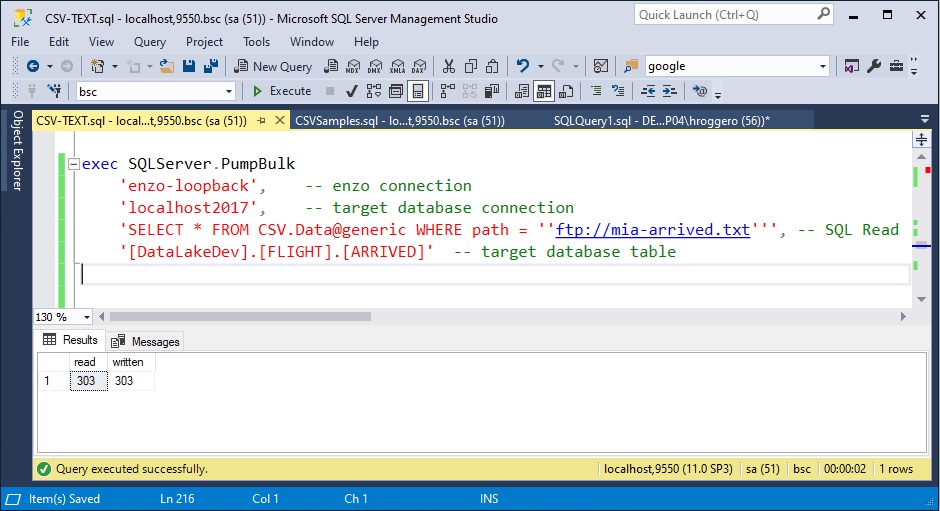
The SQL command provided as the third parameter contains single quotes; these need to be escaped properly for the SQL command to work (notice the use of two single quotes around the path parameter).
NOTE: Although the destination schema and table will be created automatically if necessary, the database must already exist. In this example, the DataLakeDev database was previously created using the CREATE DATABASE command on SQL Server.
Behind the scenes, Enzo executes the inner SQL command that retrieves data from the CSV adapter, creates the target table automatically if needed, and then uses the SQL Server BulkInsert command to import the data into SQL Server for maximum performance.
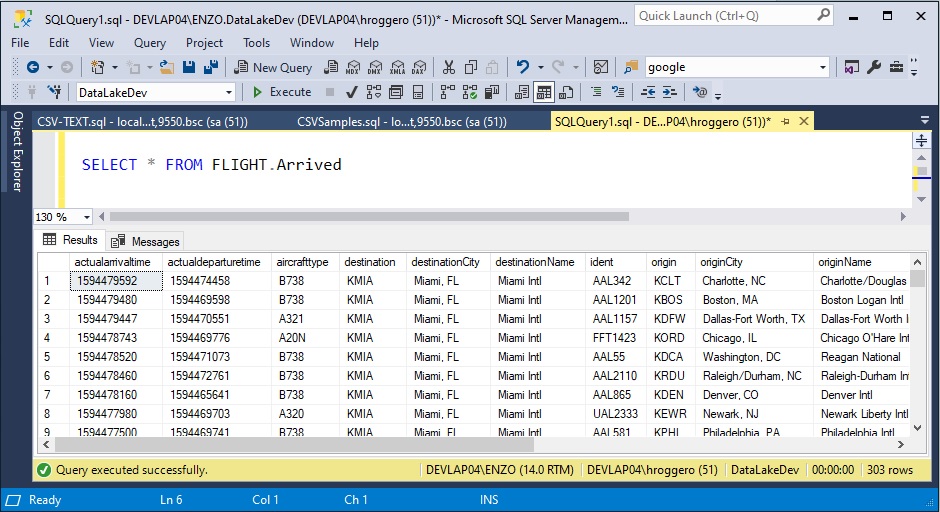
You can now query the database directly to retrieve the data from SQL Server. To do this, we are connecting to the DevLakeDev database and running a simple SELECT statement to retrieve the data that was previously imported.
NOTE: By default the target table is created with nvarchar(4000) fields automatically to ensure the data is successfully loaded. You also have the option of creating the database table manually first with the necessary fields and data types. If you create the table manually, make sure to include two required fields of type DateTime as the last columns: enzo_rowcreated and enzo_rowupdated.
Last but not least, you can also use the Data Sync tool available in Enzo Manager to perform this
task. The tool hides the complexity of calling the PumpBulk operation yourself, and exposes all
available options such as scheduling an import job and performing an Upsert operation instead
of always inserting data.
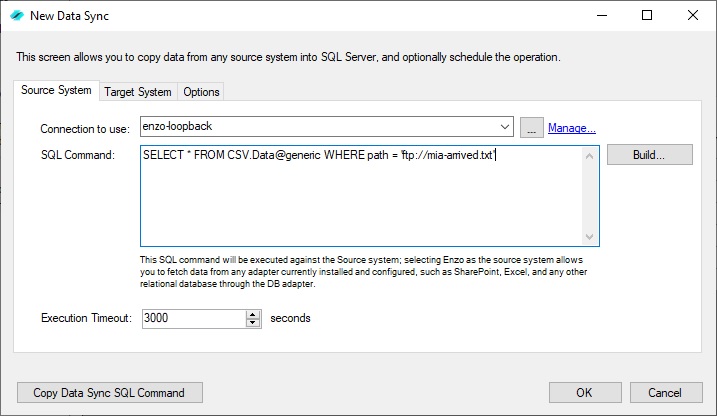
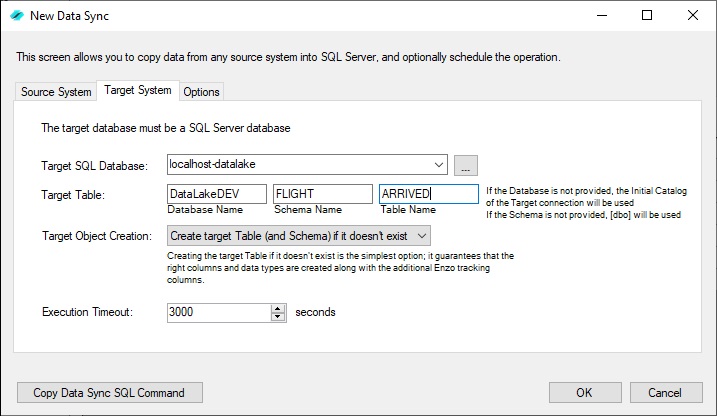
To perform the same operation as previously described, start the Data Sync tool in Enzo
Manager (Tools -> Start new Data Sync).
In the Source System tab select the Enzo loopback connection and enter the SQL command to fetch
the source data (this time, there is no need to escape the single quotes).
Next select the Target tab and choose the target database from the list of connections; enter the database name, schema and table name. The Options tab can be used to schedule the operation, and to choose Upsert options.
For more information about the Data Sync tool, including an overview of the Upsert opteration, see this blog: Quickly Building a Data Warehouse with Enzo Data Sync
In this blog post we discussed how to import CSV data into SQL Server easily using the SQLServer adapter,
and the PumpBulk operation. The data was read from an FTP source document and imported into
SQL Server using a single SQL command. We also looked at the Data Sync tool provided by Enzo Manager,
exposing all available features including scheduling and Upsert capabilities.
To try Enzo at no charge,
download the latest edition of Enzo Server on our website.
© 2023 - Enzo Unified